
Хоть с того момента и прошло 15 лет, я до сих пор помню первый день на моей первой работе. Я только-только выпустился из ВУЗа и начал работать в глобальном инвестиционном банке аналитиком. В первый день я постоянно поправлял галстук и нервно вспоминал всё, чему меня учили. В то же время втайне я задумывался, достаточно ли я хорош для делового мира. Увидев мою тревожность, начальник улыбнулся и сказал:
“Не волнуйся! Единственное, что тебе нужно помнить — модель регрессии!”
Я помню, как в тот момент я подумал: “Отлично!”. Я помнил модели регрессии: как линейную, так и логистическую. Мой начальник был прав. Моей задачей было построение статистических моделей, основанных на регрессии. К тому же, над задачами я работал не один. К слову, на то время модели регрессии считались бесспорными королевами анализа с прогнозированием. Прошло 15 лет, прошла и эра моделей регрессии. Старая королева покинула свой пост, на престол вступил новый король — XGBoost или экстремальный градиентный бустинг!
Что такое XGBoost?
XGBoost — алгоритм машинного обучения, основанный на дереве поиска решений и использующий фреймворк градиентного бустинга. В задачах предсказания, которые используют неструктурированные данные (например, изображения или текст), искусственная нейронная сеть превосходит все остальные алгоритмы или фреймворки. Но когда дело доходит до структурированных или табличных данных небольших размеров, в первенстве оказываются алгоритмы, основанные на дереве поиска решений. На инфографике можно просмотреть эволюцию таких алгоритмов.
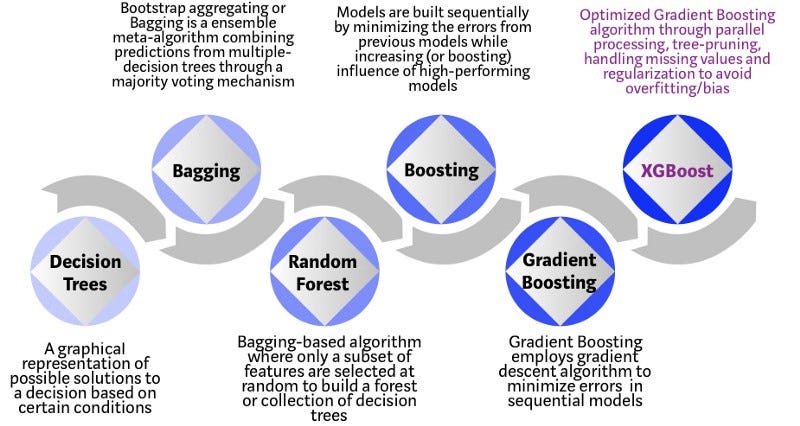
XGBoost разрабатывался как исследовательский проект Вашингтонского Университета. Tianqi Chen и Carlos Guestrin представили их работу на конференции SIGKDD в 2016 году и произвели фурор в мире машинного обучения. С момента его введения этот алгоритм не только лидировал в соревнованиях Kaggle, но и был основой нескольких отраслевых передовых приложений. В результате образовалось общество специалистов по анализу данных, вносящих вклад в проекты XGBoost с открытым исходным кодом с ~350 участниками и ~3,600 коммитами на GitHub. Особенности фреймворка:
- Широкая область применения: может быть использован для решения задач регрессии, классификации, упорядочения и пользовательских задач на предсказание.
- Совместимость: Windows, Linux и OS X.
- Языки: поддерживает большинство ведущих языков программирования, например, C++, Python, R, Java, Scala и Julia.
- Облачная интеграция: поддерживает кластеры AWS, Azure и Yarn, хорошо работает с Flink, Spark.
Интуиция за алгоритмом
Дерево принятия решений — простой в визуализации и достаточно понятный алгоритм. Однако интуиция для построения следующего поколения алгоритмов, основывающихся на деревьях, не так уж и проста. Поэтому для понимания обратимся к несложной аналогии.

Представьте, что вы специалист по подбору персонала и собеседуете нескольких отличных кандидатов. Каждый шаг эволюции алгоритмов, основанных на деревьях, может быть представлен как версия хода собеседования.
- Дерево принятия решений: Каждый специалист по подбору персонала при собеседовании кандидата ориентируется по своему списку критериев: образование, опыт работы, успешность прохождения собеседования.
- Бэггинг: Представьте, что вместо одного специалиста по подбору персонала теперь за каждым кандидатом наблюдают несколько, и каждый имеет возможность проголосовать. Этот алгоритм при принятии окончательного решения учитывает все высказанные мнения.
- Случайный лес: Этот алгоритм основан на бэггинге. Отличается он тем, что выбирает случайные признаки. То есть, каждый специалист по подбору персонала может проверить знания кандидата лишь в какой-то одной случайно выбранной области.
- Бустинг: Это альтернативный подход, в котором каждый специалист по подбору персонала основывается на оценке кандидата предыдущим специалистом. Это ускоряет процесс собеседования, так как не подходящие кандидаты сразу же отсеиваются.
- Градиентный бустинг: Частный случай бустинга, в котором ошибка минимизируется алгоритмом градиентного спуска. То есть, наименее квалифицированные кандидаты отсеиваются как можно раньше.
- XGBoost: Считайте его градиентным бустингом на стероидах (не зря, ведь он называется экстремальным градиентным бустингом). Это идеальная комбинация оптимизации ПО и железа для получения точных результатов за короткое время с минимальным использованием вычислительных ресурсов.
Почему XGBoost показывает такую хорошую производительность?
XGBoost и Gradient Boosting Machines (GBM) — ансамбли методов деревьев, которые используют принцип бустинга слабых учеников (чаще всего, алгоритм построения бинарного дерева решений) при помощи архитектуры градиентного спуска. В свою очередь, XGBoost — улучшение фреймворка GBM через системную оптимизацию и усовершенствование алгоритма.
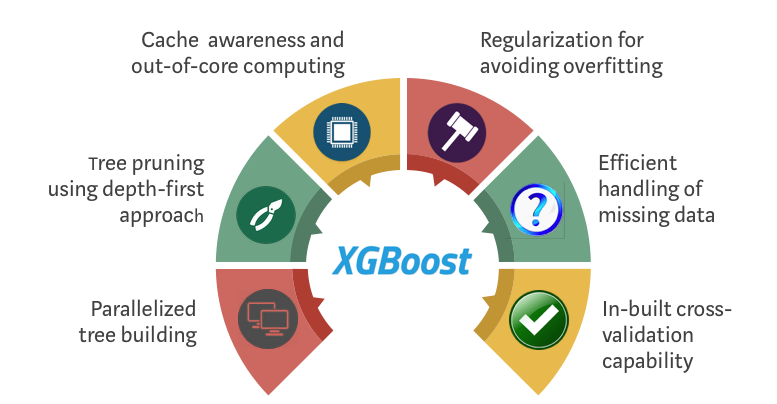
Системная оптимизация:
- Параллелизация: В XGBoost построение деревьев основано на параллелизации. Это возможно благодаря взаимозаменяемой природе циклов, используемых для построения базы для обучения: внешний цикл перечисляет листья деревьев, внутренний цикл вычисляет признаки. Нахождение цикла внутри другого мешает параллелизировать алгоритм, так как внешний цикл не может начать своё выполнение, если внутренний ещё не закончил свою работу. Поэтому для улучшения времени работы порядок циклов меняется: инициализация проходит при считывании данных, затем выполняется сортировка, использующая параллельные потоки. Эта замена улучшает производительность алгоритма, распределяя вычисления по потокам.
- Отсечение ветвей дерева: В фреймворке GBM критерий остановки для разбиения дерева зависит от критерия отрицательной потери в точке разбиения. XGBoost использует параметр максимальной глубины
max_depthвместо этого критерия и начинает обратное отсечение. Этот “глубинный” подход значительно улучшает вычислительную производительность. - Аппаратная оптимизация: Алгоритм был разработан таким образом, чтобы он оптимально использовал аппаратные ресурсы. Это достигается путём создания внутренних буферов в каждом потоке для хранения статистики градиента. Дальнейшие улучшения, как, например, вычисления вне ядра, позволяют работать с большими наборами данных, которые не помещаются в памяти компьютера.
Улучшения алгоритма:
- Регуляризация: Он штрафует сложные модели, используя как регуляризацию LASSO (L1), так и Ridge-регуляризацию (L2), для того, чтобы избежать переобучения.
- Работа с разреженными данными: Алгоритм упрощает работу с разреженными данными, в процессе обучения заполняя пропущенные значения в зависимости от значения потерь. К тому же, он позволяет работать с различными узорами разреженности.
- Метод взвешенных квантилей: XGBoost использует его для того, чтобы наиболее эффективно находить оптимальные точки разделения в случае работы со взвешенным датасетом.
- Кросс-валидация: Алгоритм использует свой собственный метод кросс-валидации на каждой итерации. То есть, нам не нужно отдельно программировать этот поиск и определять количество итераций бустинга для каждого запуска.
Где доказательство?
Мы использовали датасет Scikit-learn “Make_Classification” для того, чтобы создать миллион точек с 20 признаками (из них 2 информативных и 2 излишних). Мы протестировали несколько алгоритмов: логистическая регрессия, случайный лес, стандартный градиентный бустинг и XGBoost.
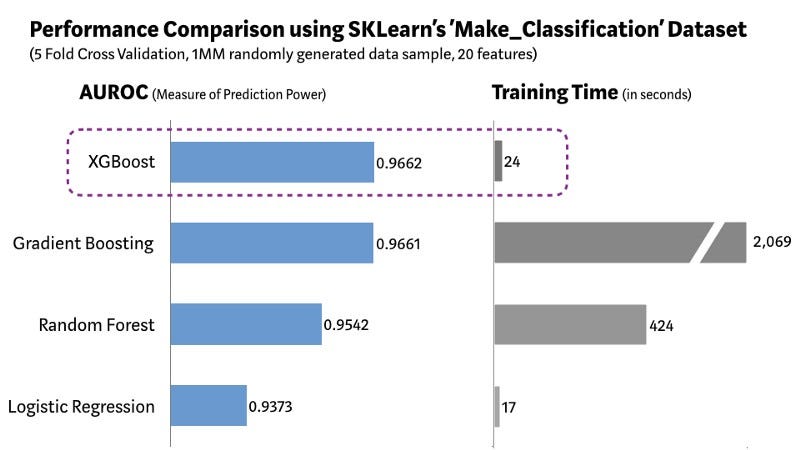
Как можно увидеть на графике выше, модель с XGBoost может похвастаться лучшей комбинацией “производительность-время обучения” среди других алгоритмов. Другие научные методы измерения производительности показали похожий результат. Поэтому неудивительно, что XGBoost достаточно часто используется в соревнованиях по анализу данных.
“Когда не знаете, какой алгоритм использовать, используйте XGBoost”, — Оуэн Жанг, победитель соревнования по улучшению контекстной рекламы от Авито на Kaggle .
Значит, можно всё время использовать XGBoost?
Когда дело доходит до машинного обучения (или даже жизни), не существует универсальных решений. Как специалисты по анализу данных, мы должны рассмотреть всевозможные алгоритмы для определённой задачи, чтобы выявить лучший из них. Но этого недостаточно. Необходимо настроить алгоритм путём подбора гиперпараметров. Также немаловажным в выборе алгоритма является его сложность, понятность и лёгкость имплементации. Именно здесь машинное обучение переходит грань между наукой и искусством, здесь происходит волшебство.
Что будет дальше?
В области машинного обучения постоянно ведутся новые исследования. На данный момент уже существует несколько жизнеспособных альтернатив XGBoost. Недавно Microsoft Research выпустила фреймворк LightGBM для градиентного бустинга. Яндекс же выпустила CatBoost, показывающий впечатляющую производительность. Создание фреймворка, превосходящего XGBoost в рамках производительности, гибкости и практичности — всего лишь вопрос времени. Но пока такого нет, XGBoost продолжит своё царствование над миром машинного обучения.
Читайте: Руководство по машинному обучению для новичков
Перевод статьи Vishal Morde и Venkat Anurag Setty: XGBoost Algorithm: Long May She Reign!




