
Изучим продвинутые техники SQL, подробно объясним используемые в них методы — концептуально и с практическими примерами, поработаем над продвинутым SQL с PostgreSQL. Базовые команды SQL не рассматриваются.
Популярность PostgreSQL постоянно увеличивается.

1. Секционирование базы данных
Таблицы, где содержится много данных, посредством секционирования разделяются на логические части — для работы с меньшим объемом данных, повышения производительности запросов и упрощения поиска.
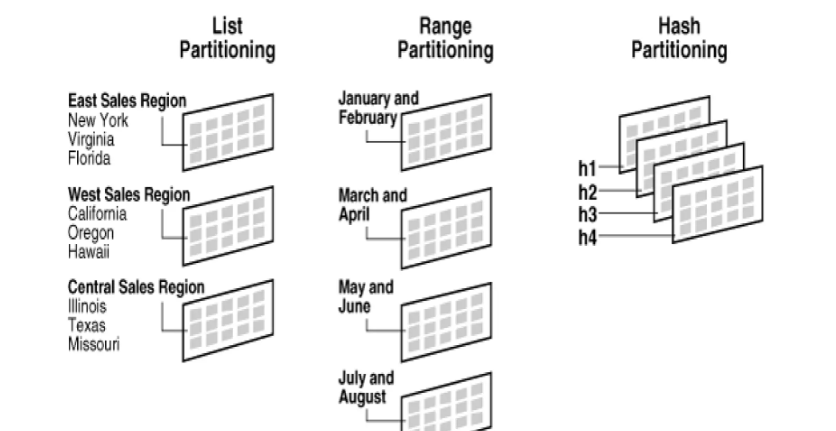
Имеется четыре разновидности секционирования, рассмотрим их назначение и проведем выборочные исследования.
- Списочным секционированием таблица разделяется на отдельные разделы по значениям конкретного столбца. Этот метод используется, когда данные можно сгруппировать по категориям, например название продукта, страна, город.
- Диапазонным секционированием таблица разделяется по конкретным датам или числам.
- Хеш-секционированием при разбиении данных значения в конкретном столбце распределяются по разделам сбалансированно, но произвольно — передаются через хеш-функцию. Этот метод предпочтителен, когда требуется равномерное распределение данных.
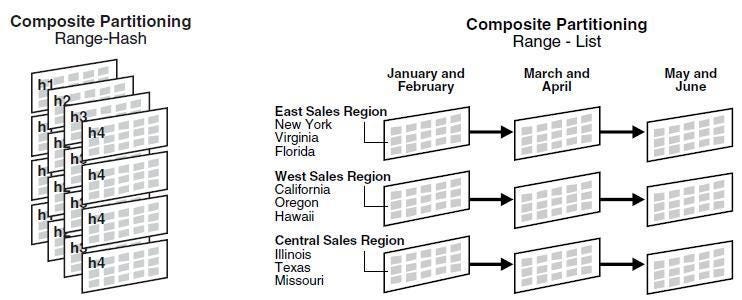
- Составное секционирование. Разделы, созданные комбинацией вышеуказанных методов, называются составными.
При проведении исследования создадим аналитические SQL-запросы PostreSQL, используя таблицу видеоигр из базы данных Kaggle.
При создании таблицы необходимо указать столбец раздела, это первичный ключ.
Пример 1. Создание таблицы для раздела по списку значений
CREATE TABLE video_games (
game_id SERIAL,
game_name TEXT,
Platform TEXT,
year_of_release INT,
Genre TEXT,
Publisher TEXT,
NA_Sales NUMERIC(10, 2),
EU_Sales NUMERIC(10, 2),
JP_Sales NUMERIC(10, 2),
Other_Sales NUMERIC(10, 2),
Global_Sales NUMERIC(10, 2),
PRIMARY KEY (game_id, Platform)
)
PARTITION BY LIST (Platform);
Создание раздела по списку значений
CREATE TABLE videogames_ps2 PARTITION OF video_games
FOR VALUES IN ('PS2');
CREATE TABLE videogames_ps3 PARTITION OF video_games
FOR VALUES IN ('PS3');
CREATE TABLE videogames_ps4 PARTITION OF video_games
FOR VALUES IN ('PS4');
-- Для других платформ создается раздел по умолчанию.
CREATE TABLE videogames_other PARTITION OF video_games
DEFAULT;
Создав раздел, добавим в таблицу video_games в PostgreSQL внешние данные. Добавляем их в каждую таблицу, создаваемую этим кодом:
COPY video_games (game_name, platform,year_of_release, genre, publisher, NA_Sales, EU_Sales, JP_Sales, Other_Sales, Global_Sales)
FROM 'C:/Users/Esra SOYLU/Desktop/videogames.csv'
DELIMITER ','
CSV HEADER
NULL AS 'N/A';
В примерах ниже этот код в качестве комментария не добавляется.
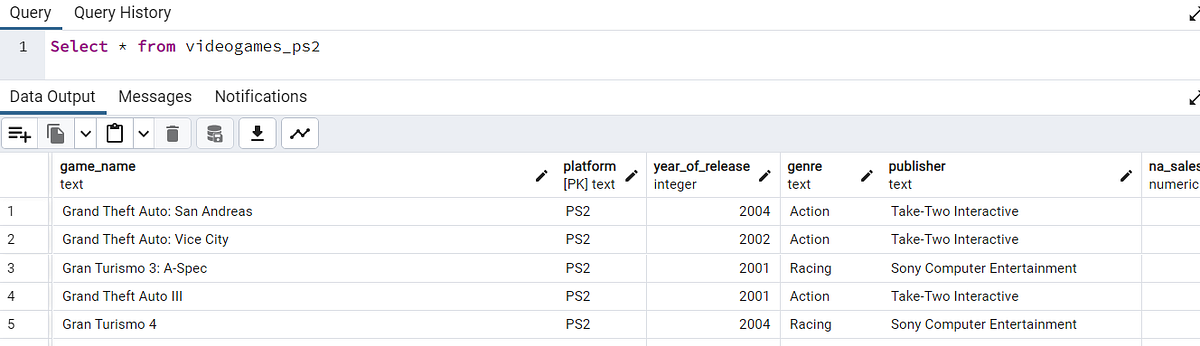
Назовем созданную в качестве раздела таблицу как videogames_ps2:
Пример 2. Раздел по диапазонам значений
Когда создается раздел по диапазонам значений, в таблице обязательно указывается PARTION Range (column_name).
Сделав таблицу, создадим раздел по диапазонам значений соответственно годам:
CREATE TABLE video_games (
game_id SERIAL,
game_name TEXT,
Platform TEXT,
year_of_release INT,
Genre TEXT,
Publisher TEXT,
NA_Sales NUMERIC(10, 2),
EU_Sales NUMERIC(10, 2),
JP_Sales NUMERIC(10, 2),
Other_Sales NUMERIC(10, 2),
Global_Sales NUMERIC(10, 2),
)
PARTITION BY RANGE (Year_of_release);
CREATE TABLE games_1980s PARTITION OF video_games
FOR VALUES FROM (1980) TO (2000);
CREATE TABLE games_2000s PARTITION OF video_games
FOR VALUES FROM (2000) TO (2010);
CREATE TABLE games_2010s PARTITION OF video_games
FOR VALUES FROM (2010) TO (2020);
CREATE TABLE games_2020s PARTITION OF video_games
FOR VALUES FROM (2020) TO (2025);
CREATE TABLE games_default PARTITION OF video_games
DEFAULT;
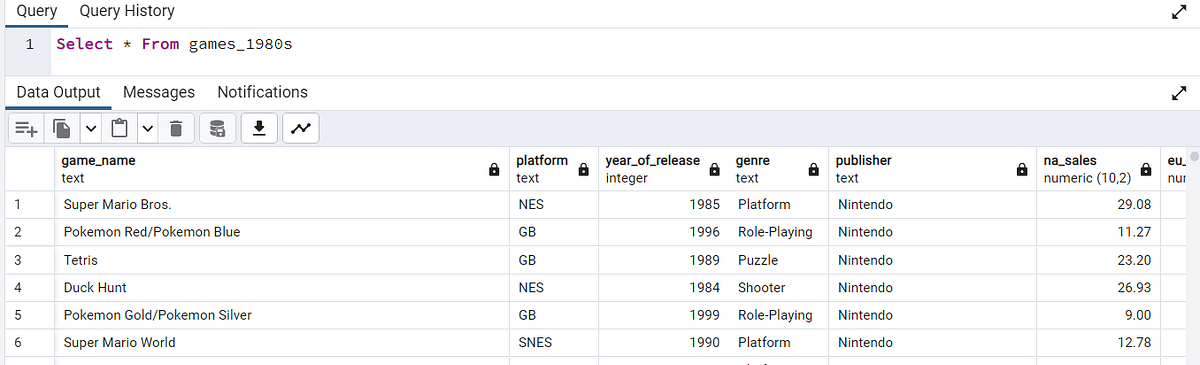
Добавим эти данные в таблицу и проанализируем. Мы вызвали ее структурой выбора разделов, созданной для диапазона лет 1980–2000, и теперь выполняем любые SQL-запросы через эту таблицу:
Сделаем код для создания хеш-раздела и составного раздела.
Пример 3. Создание хеш-раздела
CREATE TABLE video_games (
game_id SERIAL,
game_name TEXT,
platform TEXT,
year_of_release INT,
genre TEXT,
publisher TEXT,
na_sales NUMERIC(10, 2),
eu_sales NUMERIC(10, 2),
jp_sales NUMERIC(10, 2),
other_sales NUMERIC(10, 2),
global_sales NUMERIC(10, 2),
PRIMARY KEY (game_id, year_of_release)
)
PARTITION BY HASH (year_of_release);
-- 1. Раздел
CREATE TABLE video_games_p1 PARTITION OF video_games
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
-- 2. Раздел
CREATE TABLE video_games_p2 PARTITION OF video_games
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
-- 3. Раздел
CREATE TABLE video_games_p3 PARTITION OF video_games
FOR VALUES WITH (MODULUS 4, REMAINDER 2);
-- 4. Раздел
CREATE TABLE video_games_p4 PARTITION OF video_games
FOR VALUES WITH (MODULUS 4, REMAINDER 3);
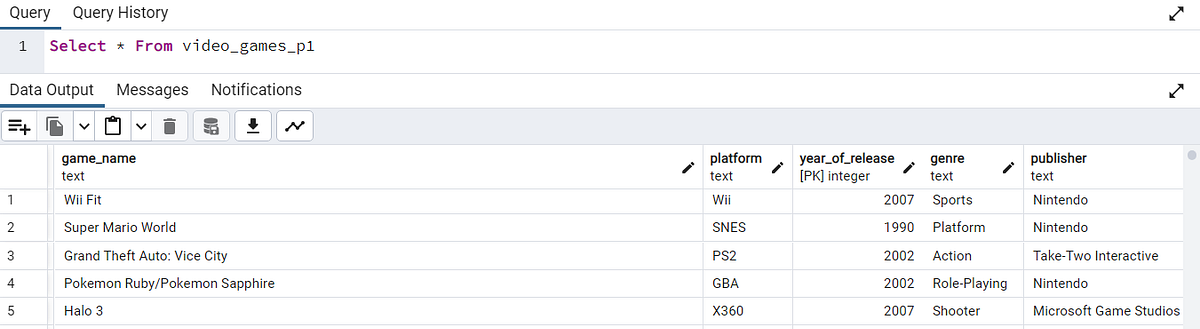
Пример 4. Создание составного раздела
Создав таблицу разделов по годам, применим разделы по платформам, применение двух разделов называется составным разделом:
CREATE TABLE video_games (
game_id SERIAL,
game_name TEXT,
platform TEXT,
year_of_release INT,
Genre TEXT,
Publisher TEXT,
NA_Sales NUMERIC(10, 2),
EU_Sales NUMERIC(10, 2),
JP_Sales NUMERIC(10, 2),
Other_Sales NUMERIC(10, 2),
Global_Sales NUMERIC(10, 2)
)
PARTITION BY RANGE (year_of_release);
-- Раздел для диапазона лет 1980–2000
CREATE TABLE video_games_1980s PARTITION OF video_games
FOR VALUES FROM (1980) TO (2000) PARTITION BY LIST (platform);
-- Раздел для диапазона лет 2000-2010
CREATE TABLE video_games_2000s PARTITION OF video_games
FOR VALUES FROM (2000) TO (2010) PARTITION BY LIST (platform);
--Списочное разделение по платформам для диапазона лет 1980–2000
CREATE TABLE video_games_1980s_wii_ps2 PARTITION OF video_games_1980s
FOR VALUES IN ('Wii', 'PS2');
--Списочное разделение по платформам для диапазона лет 2000-2010
CREATE TABLE video_games_2000s_ps3_xbox_pc PARTITION OF video_games_2000s
FOR VALUES IN ('PS3', 'XBOX', 'PC');
2. Оконные функции
2.1. Partition By с функциями сортировки SQL
Рассмотрим популярные функции сортировки с Partition By.
- Row Number: сортировка в наборе данных продолжается независимо от того, имеются ли в них одинаковые значения.
- Rank: при сортировке набора данных, если имеются одинаковые значения, за данными остается полученный при ранжировании номер. Когда появляется другое значение, номер увеличивается на пропущенное значение.
- Dense Rank: при сортировке набора данных, если имеются одинаковые значения, за данными остается полученный при ранжировании номер. Когда появляется другое значение, передается следующий по порядку номер.
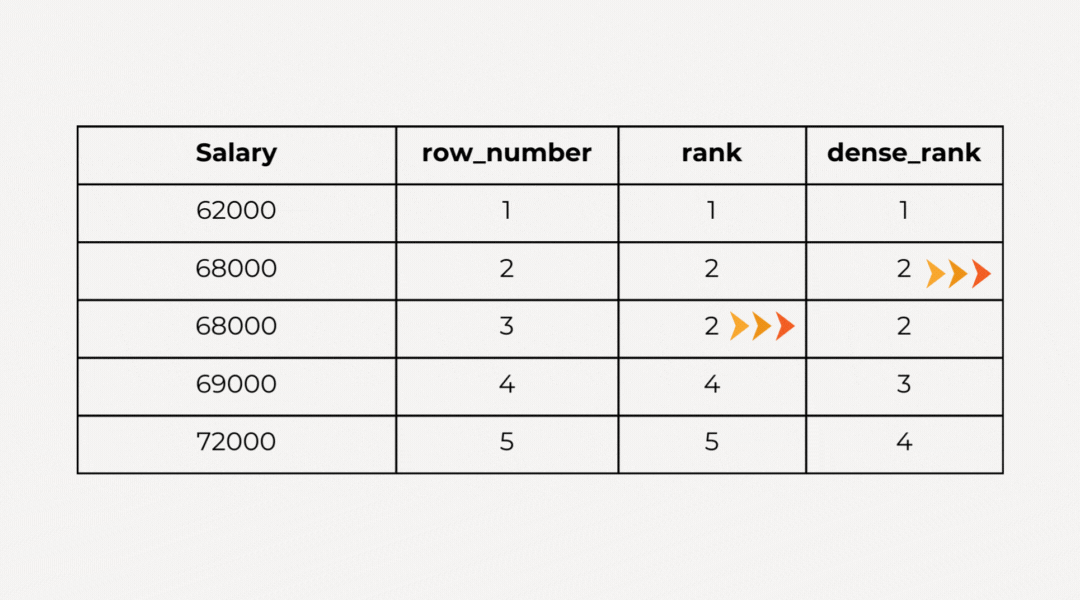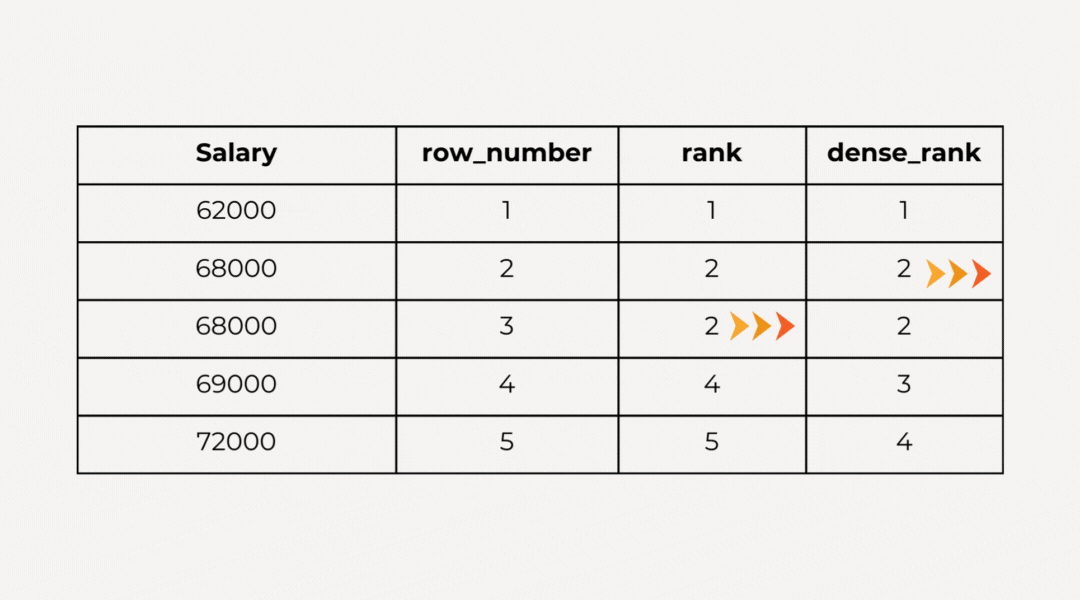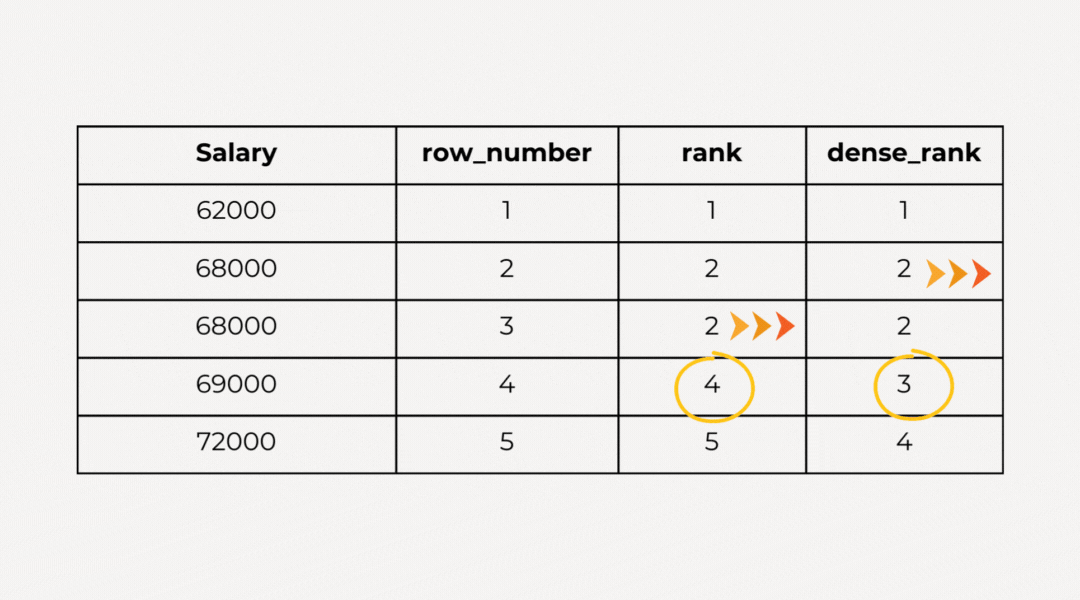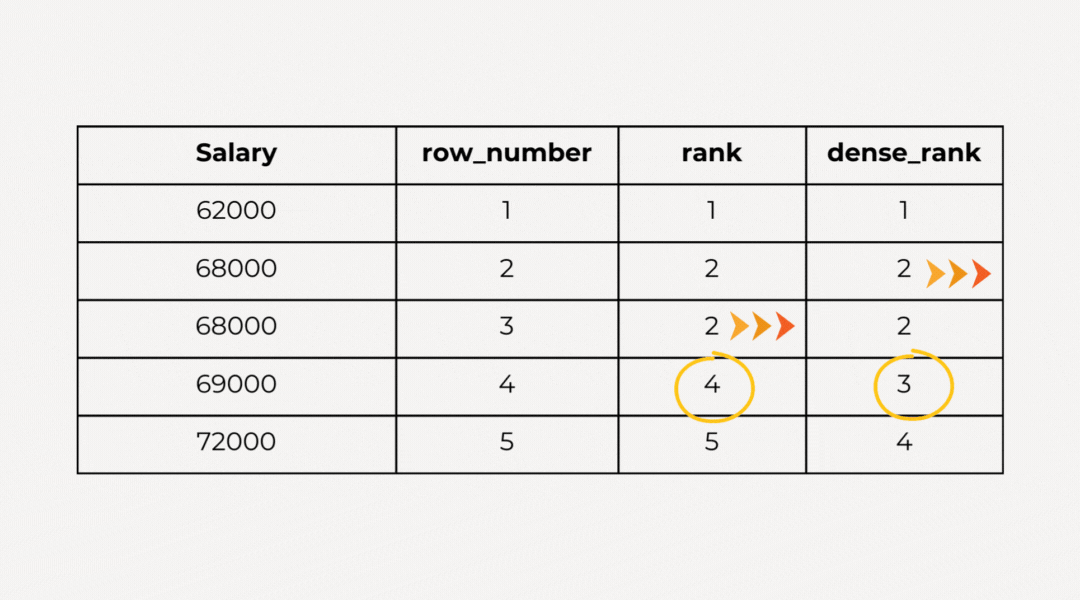
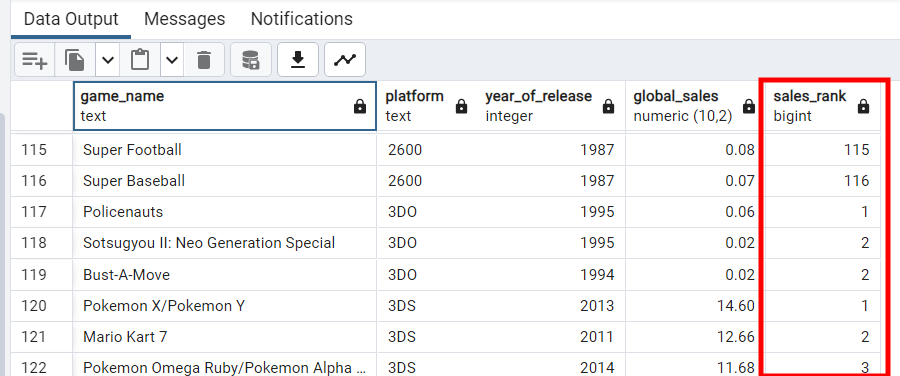
Пример: присвоим играм в каждой группе рейтинг, исходя из объема продаж. Игры с одинаковым global_sales обзаводятся одинаковым рейтингом и переводятся в следующий рейтинг. Для этого используется функция RANK(). Различия обнаруживаются применением вместо нее функций row_number() и dense_rank():
SELECT
game_name,
platform,
year_of_release,
global_sales,
RANK() OVER (PARTITION BY platform ORDER BY global_sales DESC) AS sales_rank
FROM
video_games;
2.2. Функции-значения
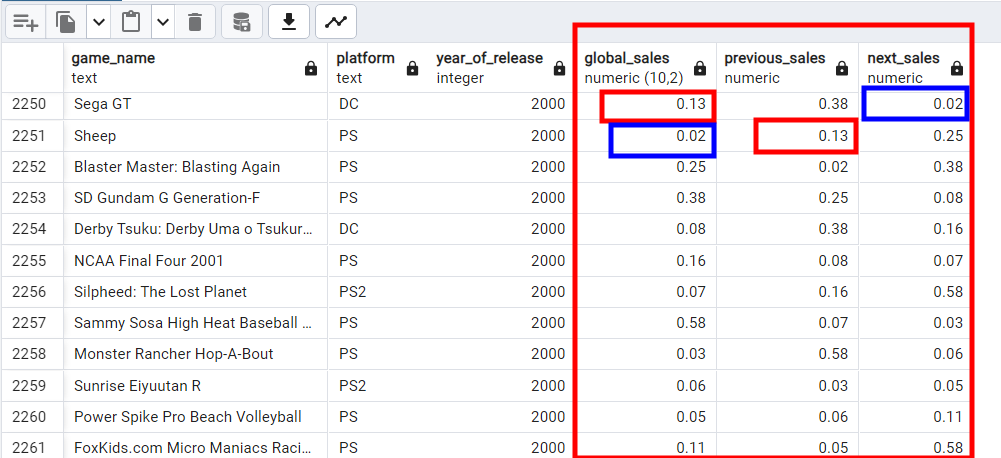
- LAG: эта функция используется с временны́ми данными и обращается к предыдущей строке из другого столбца, из полученных таким образом данных создается новый столбец.
Синтаксис: LAG (column1_name) OVER (ORDER BY column2_name) AS newcolumn_name.
- Lead: этой функцией берется значение из следующей строки и создается новый столбец. Например, в списке ежемесячных продаж функцией
Leadсоздается столбец о продажах следующего месяца.
Синтаксис: LAG (column1_name) OVER (ORDER BY column2_name) AS newcolumn_name.
SELECT
game_name,
platform,
year_of_release,
global_sales,
LAG(global_sales, 1) OVER (ORDER BY year_of_release) AS previous_sales,
LEAD(global_sales, 1) OVER (ORDER BY year_of_release) AS next_sales
FROM
video_games;
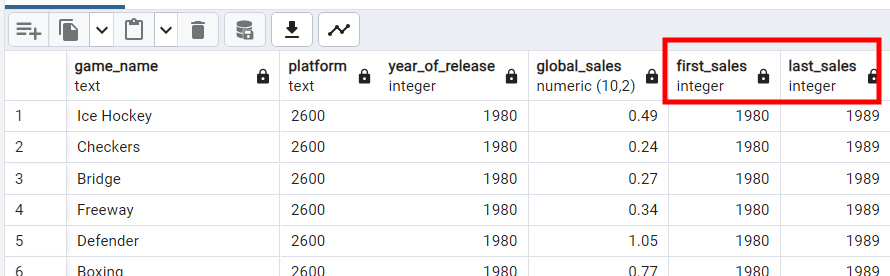
- First Value: функцией
first_valueполучается первое значение упорядоченного списка. Так, например, находится первый год продаж игры. - Last Value: функцией
last_valueполучается последнее значение отсортированного столбца. Так, соответственно, находится последний год продаж игры.
SELECT
game_name,
platform,
year_of_release,
global_sales,
FIRST_VALUE(year_of_release) OVER (PARTITION BY platform ORDER BY year_of_release) AS first_sales,
LAST_VALUE(year_of_release) OVER (PARTITION BY platform ORDER BY year_of_release RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_sales
FROM
video_games;
3. Операторы case
В SQL оператором CASE создаются условные выражения для проверки, возврата значений или генерирования новых столбцов посредством логической валидации. В каждом выражении CASE для задания условия используется WHEN, а для завершения — END.
Синтаксис:
CASE case_value
WHEN condition THEN result1
WHEN condition THEN result2
…
If not the result
END CASE;
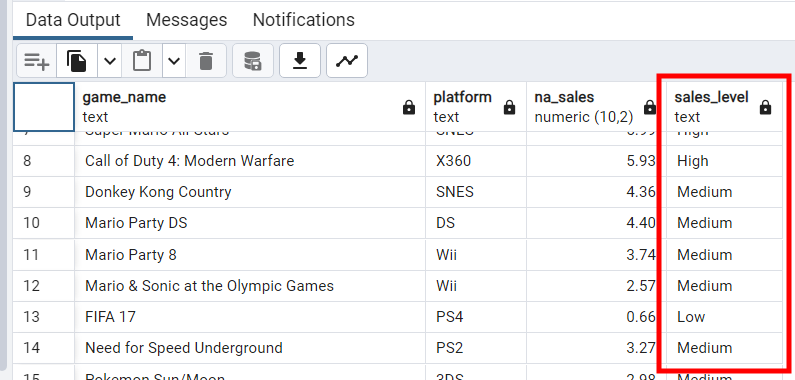
SELECT
game_name,
Platform,
NA_Sales,
CASE
WHEN NA_Sales > 5 THEN 'High'
WHEN NA_Sales BETWEEN 2 AND 5 THEN 'Medium'
ELSE 'Low'
END AS Sales_Level
FROM video_games;
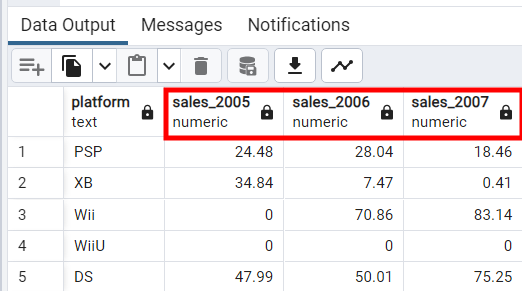
Напишем SQL-запрос об итогах продаж платформ по годам:
SELECT
platform,
SUM(CASE WHEN year_of_release = 2005 THEN NA_Sales ELSE 0 END) AS sales_2005,
SUM(CASE WHEN year_of_release = 2006 THEN NA_Sales ELSE 0 END) AS sales_2006,
SUM(CASE WHEN year_of_release = 2007 THEN NA_Sales ELSE 0 END) AS sales_2007
FROM
video_games
GROUP BY
platform;
4. Обобщенные табличные выражения
Обобщенные табличные выражения — это временно именованный результирующий набор в виде виртуальных таблиц. Этими определяемыми ключевым словом WITH выражениями внутри оператора SQL создается именованный переиспользуемый подзапрос.
Различают две разновидности структур обобщенных табличных выражений:
- Простая, нерекурсивная. Это нециклические обобщенные табличные выражения, применяемые разово для подготовки и редактирования данных или превращения подзапроса в более удобный для восприятия.
Синтаксис: WITH cte_name AS (SELECT columns FROM table_name WHERE conditions
)
SELECT columns FROM cte_name WHERE conditions;
2. Рекурсивная, повторяющаяся структура, которая начинается с запроса исходной точки и применяется в основном в иерархических структурах данных или для запросов, которые продолжаются последовательной структурой.
Синтаксис: WITH RECURSIVE cte_name AS (
Anchor Query SELECT columns FROM table_name WHERE conditions
UNION ALL
Recursive Query SELECT columns FROM tablo_name INNER JOIN cte_name ON conditions
)
SELECT * FROM cte_name;
- Anchor Query: определяется исходная точка рекурсивного запроса. Этот якорный запрос запускается единожды, результат добавляется в обобщенное табличное выражение.
- Recursive Query: на основе результатов предыдущего этапа запускается рекурсивный запрос.
- UNION ALL: якорный и рекурсивный запросы объединяются.
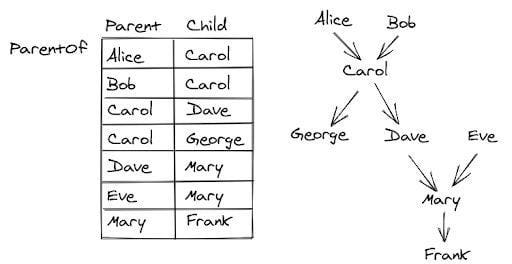
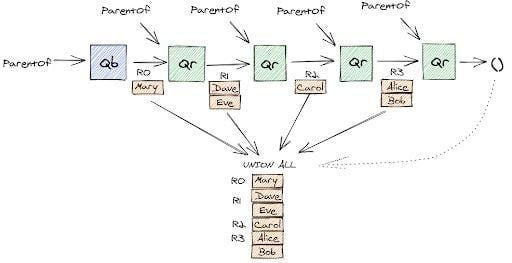
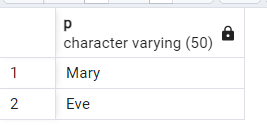
Найдем всех предков человека по имени Фрэнк, написав рекурсивный запрос с обобщенным табличным выражением:
CREATE TABLE parent_of (
parent VARCHAR(50),
child VARCHAR(50)
);
INSERT INTO parent_of (parent, child) VALUES
('Alice', 'Carol'),
('Bob', 'Carol'),
('Carol', 'George'),
('Dave', 'Mery'),
('Eve', 'Mary'),
('Mary', 'Frank')
WITH RECURSIVE Ancestor AS (SELECT parent AS p FROM parent_of WHERE child='Frank'
UNION ALL
SELECT parent FROM Ancestor, parent_of WHERE Ancestor.p = ParentOf.child)
SELECT * FROM Ancestor
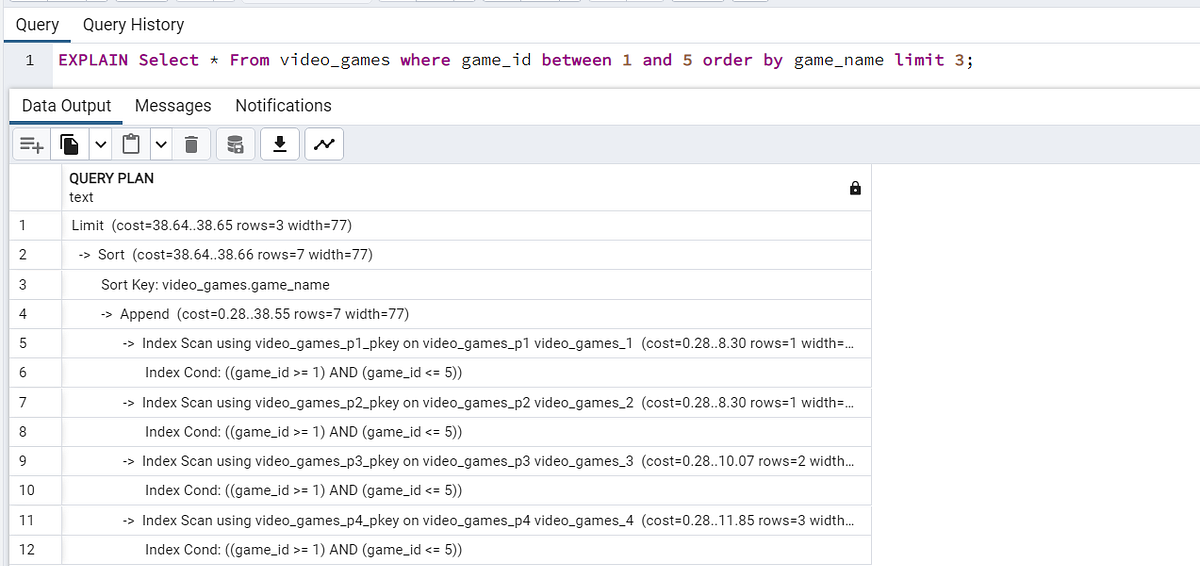
5. EXPLAIN: просмотр плана запроса
Пока разработчики Explain выполняют SQL-запросы, мы предоставляем информацию до или во время выполнения запроса и анализируем SQL-запрос, который выполним на основе результатов из этих выходных данных.
В зависимости от сложности запроса предоставляемая им информация варьируется от стратегии объединения и метода извлечения данных из таблиц до предполагаемых строк для выполнения запроса.
Синтаксис: EXPLAIN sorgu ifadesi
EXPLAIN Select * from video_games where game_id between 1 and 5 order by game_name limit 3;
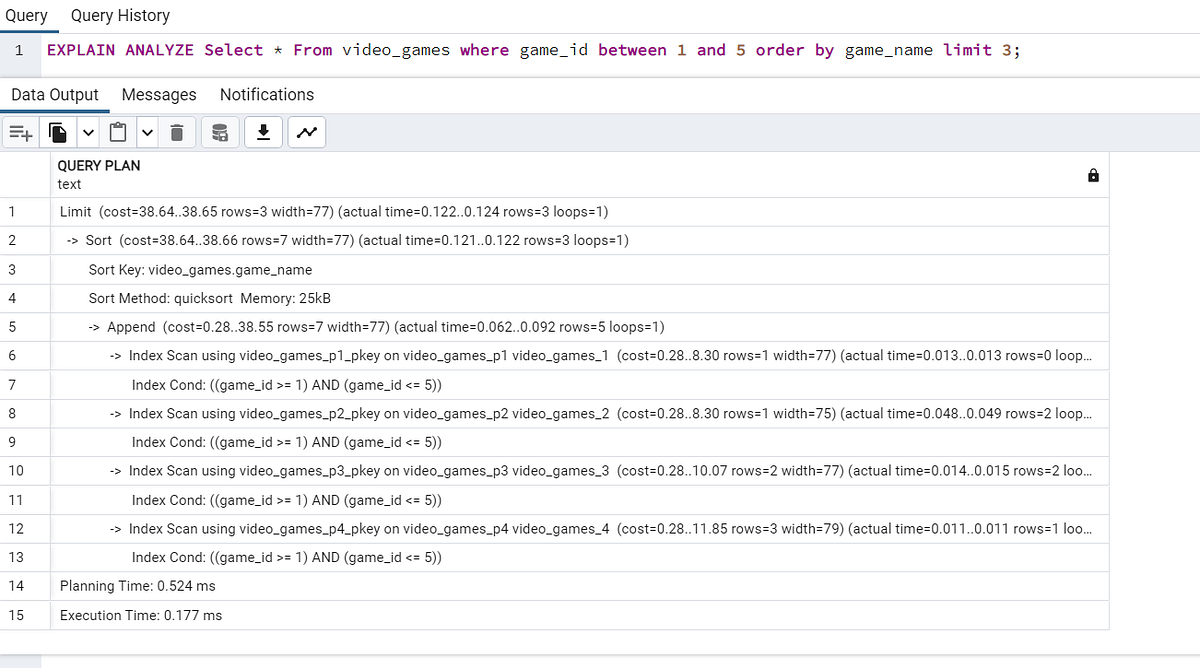
Командой EXPLAIN ANALYZE получается информация о продолжительности выполнения запроса, сортировки и объединения, что невозможно осуществить в памяти, и т. д.
6. Index
Нужный фрагмент данных разыскивается машиной в каждой строке большой базы данных, пока он наконец не найдется. Если искомые данные обнаруживаются ближе к концу, этот запрос будет выполняться долго. Но проблема решается индексной структурой, благодаря которой запрос данных Index ускоряется. Index tipleri
Синтаксис: CREATE INDEX index_name ON table_name (column_name1, column_name2);
CREATE INDEX idx_name
ON employees (first_name, last_name);
SELECT *
FROM employees
WHERE first_name= 'ESRA';
7. Триггеры
Когда в SQL запускается запрос, именно структура кода позволяет выполнить другой запрос. Ею выполняется конкретная операция как результат изменения, внесенного в базу данных.
Синтаксис:
CREATE TRIGGER trigger_name {BEFORE | AFTER}
{INSERT | UPDATE | DELETE}
ON table_name [FOR EACH ROW]
BEGIN
Trigger action commands
END;
- trigger_name: название создаваемого триггера.
- BEFORE | AFTER: указывается, до или после операции изменения данных запустится триггер.
- INSERT | UPDATE | DELETE: указывается операция изменения данных, для которой запустится триггер.
- ON table_name: указывается таблица, в которой запустится триггер.
- FOR EACH ROW: обеспечивается запуск триггера для каждой строки.
- BEGIN … END: в этот диапазон включаются SQL-команды, выполняемые в триггере.
CREATE OR REPLACE FUNCTION set_created_at()
RETURNS TRIGGER AS $$
BEGIN
NEW.created_at := NOW();
RETURN NEW;
END;
CREATE TRIGGER before_insert_videogame
BEFORE INSERT ON video_games
FOR EACH ROW
EXECUTE FUNCTION set_created_at();
INSERT INTO video_games (game_name, platform, year_of_release, genre, publisher, na_sales, eu_sales, jp_sales, other_sales, global_sales)
VALUES ('Galactic Conquest', 'PS5', 2024, 'Sci-Fi RPG', 'FutureTech Games', 1.20, 0.95, 0.30, 0.10, 2.55);

8. Временные таблицы
Временные таблицы существуют только в течение конкретной транзакции или сеанса и автоматически удаляются по его окончании. В них обычно хранятся временные данные, выполняются промежуточные вычислительные операции или временно содержатся данные операций над базой данных.
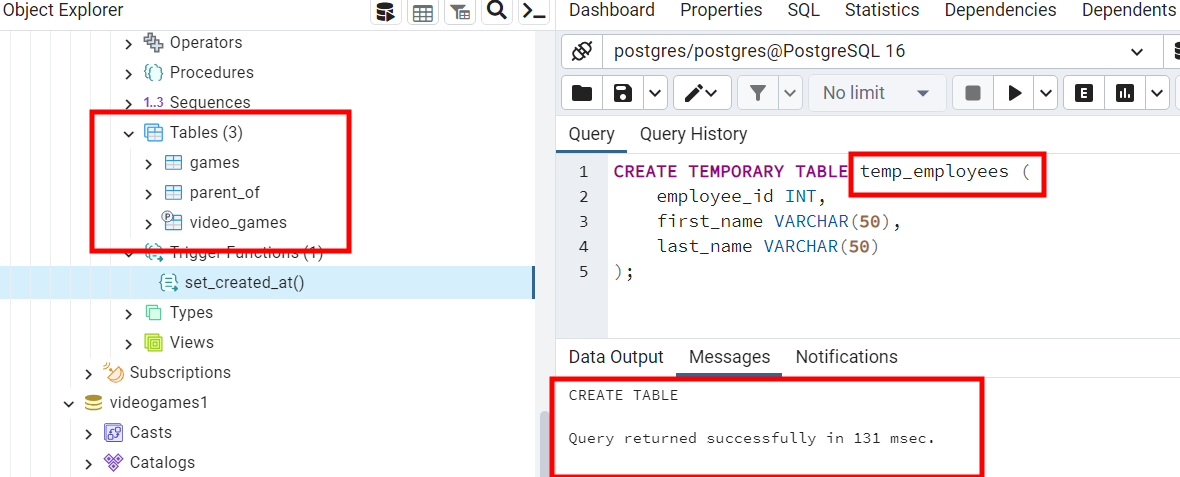
Синтаксис: CREATE TEMPORARY TABLE table_name(column1 type,column2 type, … );
CREATE TEMPORARY TABLE temp_employees (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50)
);
Эта временная таблица temp_employees создана с Create Temporary, поэтому не отображается в области таблиц.
9. Хранимые процедуры
Хранимые процедуры — это группа запросов SQL, которые можно использовать, не перезаписывая. Ею не возвращается результат и выполняются такие операции, как обновление, удаление или добавление в таблицу.
Синтаксис: CREATE PROCEDURE procedure_name [ (parameters) ]
AS
BEGIN
SQL commands
END;
CREATE OR REPLACE PROCEDURE insert_game_data(
game_name TEXT,
platform_name TEXT,
release_year INT,
game_genre TEXT,
game_publisher TEXT,
na_sales NUMERIC,
eu_sales NUMERIC,
jp_sales NUMERIC,
other_sales NUMERIC,
global_sales NUMERIC
)
LANGUAGE SQL
BEGIN ATOMIC
INSERT INTO video_games (
game_name,
platform,
year_of_release,
genre,
publisher,
na_sales,
eu_sales,
jp_sales,
other_sales,
global_sales
)
VALUES (
game_name,
platform_name,
release_year,
game_genre,
game_publisher,
na_sales,
eu_sales,
jp_sales,
other_sales,
global_sales
);
END;
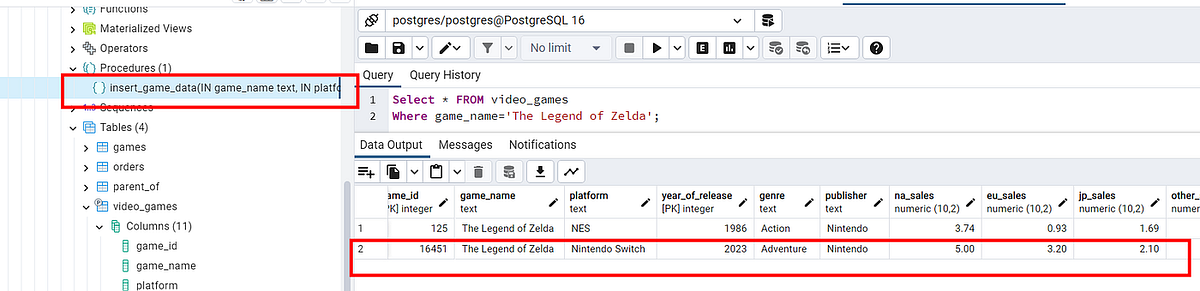
Вызывающая процедура
CALL insert_game_data(
'The Legend of Zelda',
'Nintendo Switch',
2023,
'Adventure',
'Nintendo',
5.0,
3.2,
2.1,
0.5,
10.8
);
10. VIEW
Созданием View запросы в PostgreSQL упрощаются: нужные SQL-таблицы собираются в виртуальную таблицу, как реальную. Еще легче создать View, используя вместо структур JOIN только структуры VIEW.
Синтаксис: CREATE VIEW view_name AS query;
Чтобы в этой базе данных с таблицей employees, departments and sales сделать view, в котором объединена информация о сотрудниках и продажах, создадим такой код:
CREATE VIEW sales_team_info AS
SELECT
employees.employee_id,
employees.first_name,
employees.last_name,
employees.email,
employees.phone_number,
departments.department_name,
sales.total_sales,
sales.region
FROM
employees
INNER JOIN departments ON employees.department_id = departments.department_id
INNER JOIN sales ON employees.employee_id = sales.employee_id
WHERE departments.department_name='Sales';
11. Определяемые пользователем функции
Этими функциями расширяется встроенная функциональность SQL — создаются пользовательские функции:
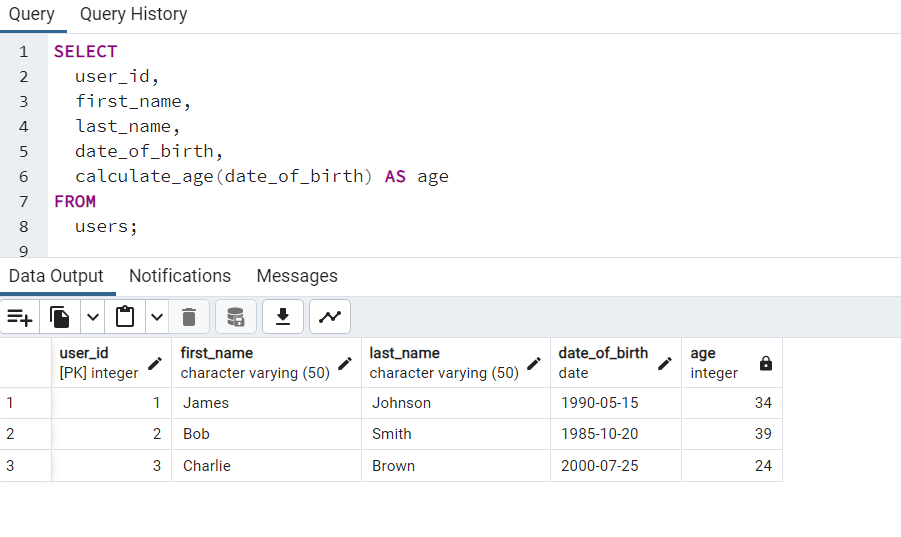
CREATE OR REPLACE FUNCTION calculate_age(date_of_birth DATE)
RETURNS INTEGER AS $$
BEGIN
RETURN DATE_PART('year', AGE(date_of_birth));
END;
$$ LANGUAGE plpgsql;
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
date_of_birth DATE
);
Добавим данные:
INSERT INTO users (first_name, last_name, date_of_birth)
VALUES
('James', 'Johnson', '1990-05-15'),
('Bob', 'Smith', '1985-10-20'),
('Charlie', 'Brown', '2000-07-25');
Посмотрите: значения в столбце Age таблицы создаются функцией автоматически.
12. Подзапрос
Подзапрос — это запрос, вложенный в другой запрос. Подзапрос также называют внутренним или вложенным запросом. IN и EXISTS — две важные, часто используемые в подзапросах SQL функции.
С помощью IN возвращаются значения запрошенных данных, а структурой EXISTS проверяется наличие нужных данных. Если подзапросом возвращается хотя бы одна строка, возвращается TRUE, в противном случае — FALSE.
Синтаксис: SELECT column1, column2,.. FROM table_name
WHERE column_name IN (subquery);
SELECT column1, column2, …FROM table_name
WHERE EXISTS (subquery);
Пример кода:
SELECT *
FROM video_games
WHERE game_id IN (SELECT game_id FROM video_games WHERE publisher = 'Nintendo');
SELECT *
FROM video_games g1
WHERE EXISTS (
SELECT 1
FROM video_games g2
WHERE g2.publisher = 'Nintendo'
AND g2.game_id = g1.game_id
)
AND g1.year_of_release < 2020;
13. Работа с данными JSON
JSON, или нотация объектов JavaScript, является гибким форматом данных, которым, в частности, поддерживается работа с полуструктурированными данными. Будучи структурой пар ключ-значение, формат JSON — это идеальное решение для передачи данных между веб-приложениями. Поработаем с функциями JSON.
Создание данных в формате JSON
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
customer_name TEXT,
order_details JSON
);
INSERT INTO orders (customer_name, order_details)
VALUES
('Esra', '{"item": "Laptop", "quantity": 1, "price": 45000}'),
('Esma', '{"item": "Phone", "quantity": 2, "price": 25000}');
Операторы JSON

Из таблицы заказов извлекается имя каждого клиента вместе со сведениями о товаре и цене, которые хранятся в столбце order_details в формате JSON:
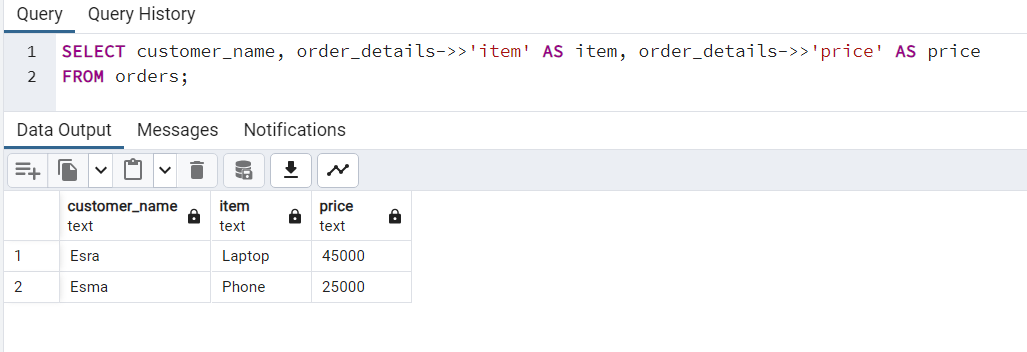
Чтобы получить записи со значением элемента Laptop в столбце order_details в формате JSON, выполним запрос в таблицу Orders:
SELECT *
FROM orders
WHERE order_details->>'item' = 'Laptop';

Поработаем с примером функции json.
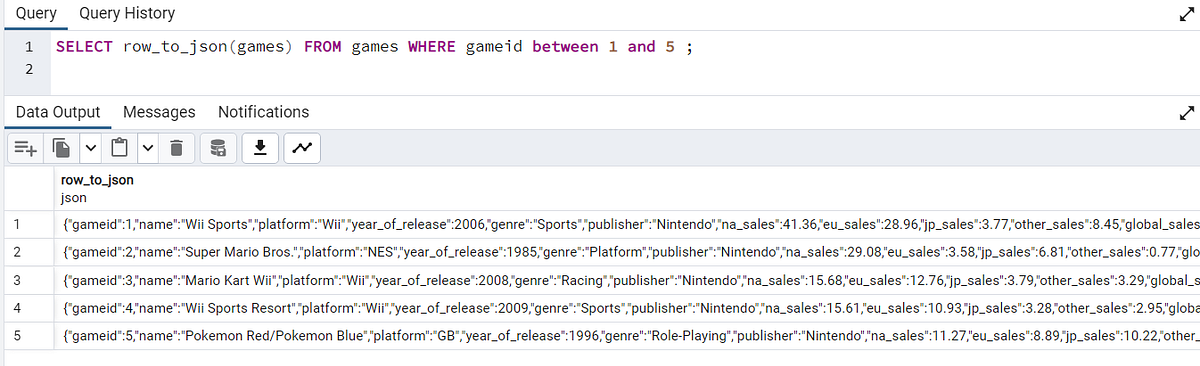
row_to_json: в качестве ввода этой функцией принимается строка базы данных и возвращается объект JSON, в котором содержатся все столбцы в строке:
SELECT row_to_json(games) FROM games WHERE gameid between 1 and 5;
14. Многоверсионное управление конкурентным доступом
Для контроля доступа к данным в PostgreSQL используется многоверсионное управление конкурентным доступом. Благодаря этой системе контроля, в базе данных в одно и то же время выполняется множество транзакций и обеспечивается согласованность данных.
Многоверсионное управление конкурентным доступом применяется для согласованного выполнения одновременных операций считывания и записи, при котором они не становятся препятствиями друг для друга.
-- Транзакция начинается
BEGIN;
-- Вставляется новая запись об игре
INSERT INTO games (name, genre, release_of_date, price)
VALUES ('The Last of Us Part II', 'Action', '2020-06-19', 59.99);
-- Меняется цена имеющейся игры
UPDATE games
SET price = 49.99
WHERE title = 'The Last of Us Part II';
-- Умышленная ошибка для моделирования сбоя
DELETE FROM games WHERE id = 99999;
-- Если все операции выполняются, транзакция фиксируется
COMMIT;
-- Если что-то не так, транзакция откатывается
ROLLBACK;
15. Настройка производительности PostgreSQL
Для выполнения различных настроек и конфигурирования с целью повышения производительности базы данных в PostgreSQL имеется соответствующий функционал. Здесь операции по настройке производительности применяются для таких целей, как оптимизация управления ресурсами, ускорение отклика на запросы, снижение нагрузки на ввод/вывод.
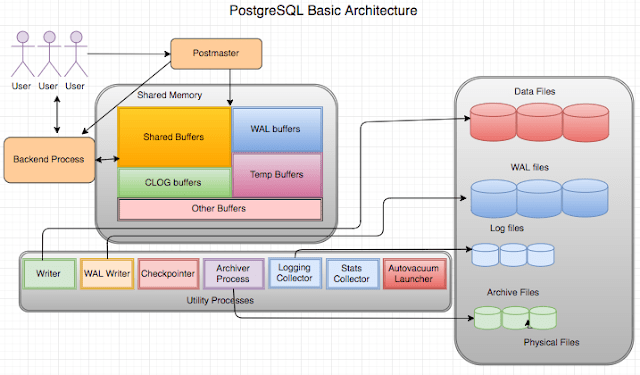
С управлением ресурсами связано множество параметров. Вот соответствующие функции:
- shared_buffers: задается объем памяти, используемый сервером базы данных для буферов разделяемой памяти.
- work_mem: указывается объем памяти, используемый операциями внутренней сортировки и хеш-таблицами перед записью во временные файлы на диске.
- vacuum_cost_delay: указывается время в миллисекундах, по истечении которого при превышении лимита затрат процесс переводится в режим ожидания.
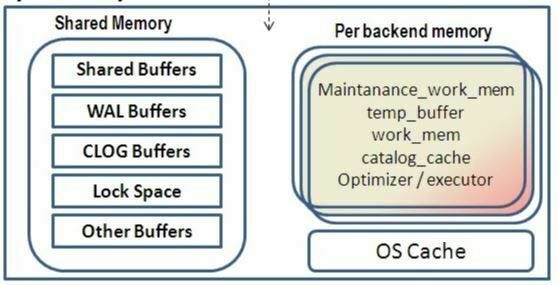
Подробнее об используемых во вспомогательном процессе параметрах — здесь.
Ознакомьтесь с руководством по функциям SQL.
Читайте также:
- Основные методы оптимизации базы данных SQL
- Как последовательно писать аналитические SQL-запросы за 8 шагов
- Руководство по SQL: Как лучше писать запросы
Читайте нас в Telegram, VK и Дзен
Перевод статьи Esra Soylu: Advanced SQL Techniques





