

Мое первое погружение в мир данных состоялось во время учебы в колледже. Меня очаровала простота языка SQL. Он казался таким же простым, как и разговорный английский. С командами типа SELECT можно видеть результат работы. К тому же в SQL нет ни скрытых смыслов, ни сложного синтаксиса.
Первоначальный восторг начал ослабевать, когда мне довелось столкнуться с первой проблемой: оконными функциями и их оператором PARTITION BY. Внезапно ясное небо моего изучения SQL омрачилось, и впереди замаячили грозные тучи сложных запросов.
Но не стоило волноваться! Все не так страшно, как казалось на первый взгляд. Если вы новичок в сфере науки о данных, не нужно бояться: немного терпения и практики — и вы освоите необходимые концепции. В этой статье я расскажу о различиях между PARTITION BY и GROUP BY и помогу понять их уникальные роли и случаи использования.
Готовы? Открывайте IDE и приступайте к работе!
“BY” относится… к разным вещам?
То, что оба оператора содержат «BY«, не означает, что они делают одно и то же. Хорошо, что дела обстоят именно так, ведь наличие специальных функций для решения конкретных задач делает SQL мощным и универсальным языком.
На первый взгляд результаты использования этих операторов могут показаться похожими, но все же есть ключевые различия. Очень важно понимать разницу между PARTITION BY и GROUP BY, чтобы знать, когда использовать тот или другой оператор.
Разберем отдельно GROUP BY и PARTITION BY
Проведем группировку
Самое важное и удивительное в операторе GROUP BY то, что оно довольно непокорный и всегда используется отдельно.
Вот пример:

Как видите, оператор GROUP BY используется независимо. Он требуется SQL, когда вы используете функцию агрегирования в операторе SELECT. GROUP BY группирует строки с одинаковыми значениями в определенных столбцах в итоговые строки.
А теперь разделим данные
PARTITION BY — оператор, который любит находиться рядом с другими ключевыми словами SQL и используется в операторе OVER оконной функции. PARTITION BY делит результирующий набор на разделы, к которым применяется оконная функция.
Вот еще один пример:

Этот оператор разбивает результаты на разделы или окна. На основе этого мы будем применять агрегацию или функцию, установленную в начале. После того как вы напишете эту часть, вам также нужно будет разработать область, на базе которой вы делаете разделение.
В чем же все-таки разница?
Немного терпения, разбор еще не окончен. Разберемся с отличиями этих двух операторов.
- Суть действия. Оператор
GROUP BYлюбит контролировать все, поэтому, когда мы используем его в запросе, он реструктурирует весь набор результатов, обобщая данные на основе групповых критериев. С другой стороны,PARTITION BYдействует более целенаправленно и добавляет дополнительные столбцы только на основе критериев разделения, позволяя проводить детальный анализ в рамках каждого раздела.
- Сокращение строк. Поскольку
GROUP BYконтролирует структуру набора результатов, он возвращает меньше строк, группируя в итоговые строки данные с одинаковыми значениями в конкретных столбцах.PARTITION BYне «играет» с количеством строк; вместо этого он добавляет дополнительную информацию (вычисляемые столбцы) на основе разделения, определенного для каждой строки.
- Доступные функции агрегирования.
GROUP BYпозволяет использовать такие функции агрегирования, какSUM,AVG,MIN,MAXиCOUNT.PARTITION BY, используемый в оконных функциях, также поддерживает эти функции агрегирования, но дополнительно обеспечивает доступ к функциям ранжирования и временных рядов, таким какROW_NUMBER,RANK,DENSE_RANK,LAGиLEAD.
- Чрезмерное усложнение (сложность запроса). Использование
GROUP BYможет слишком усложнить запросы, поскольку требует включения всех неагрегированных столбцов как в операторSELECT, так и в операторGROUP BY. Это делает запрос сложным и менее гибким, особенно если вы хотите агрегировать определенные столбцы, но при этом вам нужны другие подробные данные. А вот операторPARTITION BYпозволяет включать любой столбец в операторSELECTбез включения его в критерии разделения, что обеспечивает большую гибкость.
- Производительность. Специалисты по программированию всегда озабочены производительностью и оптимизацией, верно? Использование
GROUP BYможет быть ресурсоемким, поскольку объединяет строки в группы, особенно при работе с большими наборами данных. С другой стороны,PARTITION BYвместе с оконными функциями выполняет вычисления по разделам без уменьшения количества строк, сохраняя гранулярность набора данных и добавляя необходимые вычисления в виде новых столбцов.
Пришло время увидеть операторы в действии
Теория — это хорошо, но если вы, как и я, предпочитаете учиться на практике, то пора ознакомиться с конкретными примерами.
Предположим, у нас есть таблица, содержащая информацию о транзакциях, совершенных различными клиентами:
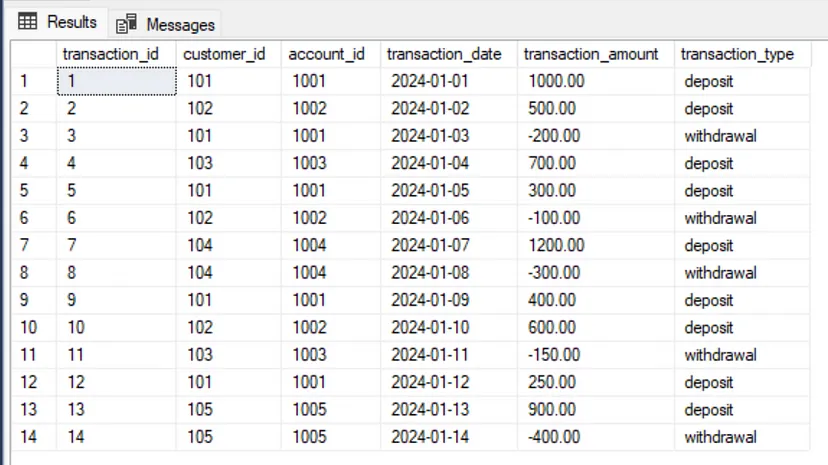
Нам нужно сообщить о ситуации и показать сумму transaction_amount для каждого клиента. Довольно просто, верно?
SELECT
customer_id,
SUM(transaction_amount) AS total_amount
FROM transactions
GROUP BY customer_id;
И у нас будет такой результат:
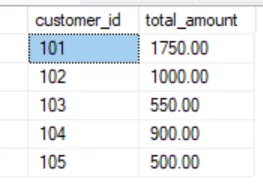
Готово!
Но через полчаса приходит запрос на изменение: теперь заказчику нужно видеть такие детали, как customer_id, account_id, transaction_date, transaction_amount, transaction_type, а также общую сумму по каждому клиенту. Как этого добиться?
Посмотрим, что от нас требуется. Прежде всего, нам нужна общая сумма по каждому клиенту, а значит, мы будем использовать функцию агрегирования типа SUM.
По какой-то причине мы решили модифицировать скрипт и добавить нужные столбцы, поэтому наш запрос выглядит следующим образом:
SELECT
customer_id,
account_id,
transaction_date,
transaction_amount,
transaction_type,
SUM(transaction_amount) AS total_amount
FROM transactions
GROUP BY customer_id;
Вы его запускаете и видите такой результат:

Но как это могло произойти? Все просто: мы забыли, что оператор GROUP BY должен содержать все неагрегированные столбцы из SELECT.
Поэтому наш запрос должен быть таким:
SELECT
customer_id,
account_id,
transaction_date,
transaction_amount,
transaction_type,
SUM(transaction_amount) AS total_amount
FROM transactions
GROUP BY
customer_id,
account_id,
transaction_date,
transaction_amount,
transaction_type;
Результат:
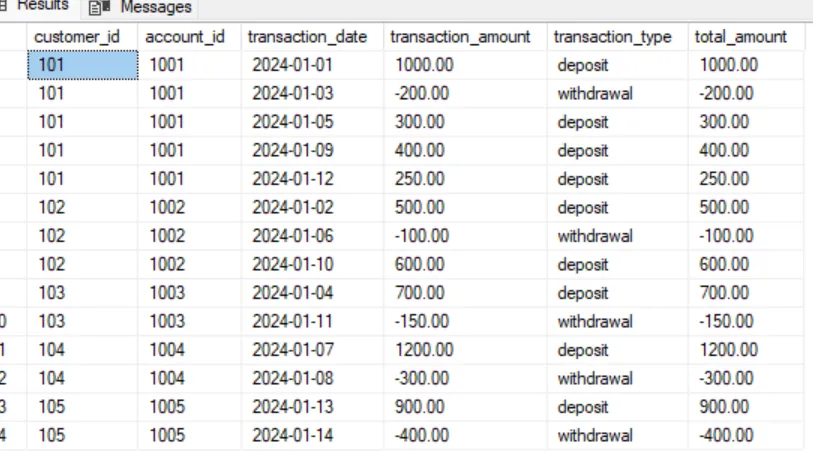
Хм… кажется, что-то не так. Как клиент с customer_id = 101 может иметь разную общую сумму для каждой своей записи, когда она должна быть только одна?
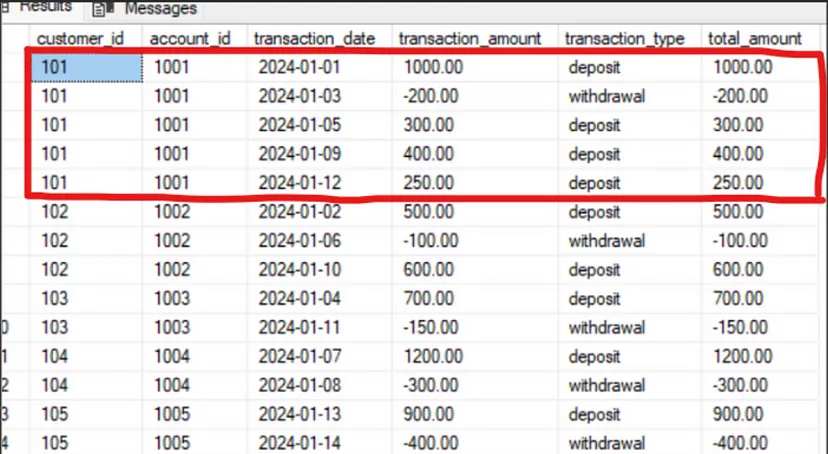
Если мы сложим значения из transaction_amount вручную или выполним первый запуск SELECT, то обнаружим, что total_amount для customer_id = 101 составляет 1750. Значит, что-то действительно не так.
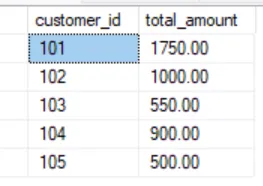
Нужно изменить тактику
Что, если мы сделаем «окна» для каждого customer_id? Таким образом, мы изолируем каждого клиента и вычислим общую сумму, не записывая все эти столбцы дважды в один и тот же оператор SELECT.
SELECT
customer_id,
account_id,
transaction_date,
transaction_amount,
transaction_type,
SUM(transaction_amount) OVER(PARTITION BY customer_id) AS total_amount_per_customer
FROM transactions;
Результат показан ниже:
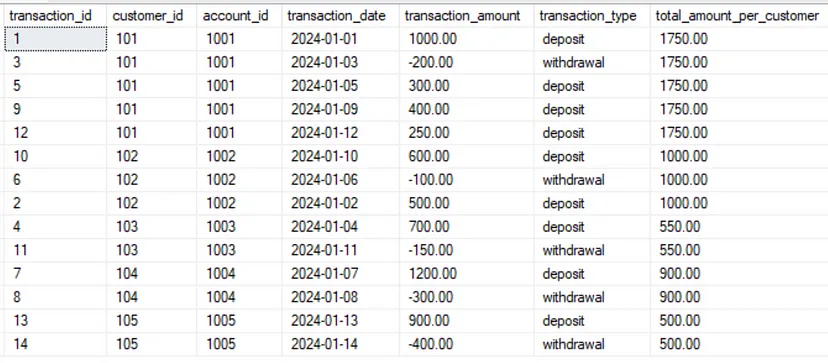
Если мы снова выполним проверку, то увидим, что теперь суммы совпадают, а также у нас есть вся необходимая информация.
Когда что использовать?
Известно, что оконная функция, содержащая оператор PARTITION BY, используется для расширенной аналитики и позволяет выполнять сложные вычисления над набором строк таблицы. Оператор GROUP BY применяется для группировки строк с одинаковыми значениями в определенных столбцах в итоговые строки (например, общие продажи по клиентам или средняя зарплата по отделам). Ниже приведены примеры сценариев и рекомендуемые подходы.
Используйте GROUP BY в следующих случаях.
- Вам нужно обобщить данные, сгруппировав строки, имеющие одинаковые значения в определенных столбцах, и выполнить для них функции агрегирования (например, получить общую сумму транзакций для каждого клиента):
SELECT customer_id, SUM(transaction_amount) AS total_amount FROM transactions GROUP BY customer_id;
- Вам нужно подсчитать количество строк в каждой группе (например, количество транзакций по счету):
SELECT account_id, COUNT(*) AS transaction_count
FROM transactions
GROUP BY account_id;
- Вам нужно найти дублирующиеся значения с помощью оператора
HAVING(например, найти дублирующиеся транзакции):
SELECT transaction_id, count(*)
FROM transactions
GROUP BY transaction_id
HAVING count(*) > 1
Используйте PARTITION BY в следующих случаях.
- Вам нужно вычислить текущие итоги или совокупную сумму для каждой строки в разделе:
SELECT
transaction_id,
customer_id,
transaction_amount,
SUM(transaction_amount) OVER(PARTITION BY customer_id ORDER BY transaction_date) AS running_total
FROM transactions;
- Вы хотите присвоить ранги строкам внутри раздела на основе определенного порядка (например, найти вторую зарплату):
SELECT
transaction_id,
customer_id,
transaction_amount,
RANK() OVER(PARTITION BY customer_id ORDER BY transaction_amount DESC) AS transaction_rank
FROM transactions;
- Вам нужно получить доступ к данным из предыдущих или последующих строк в одном разделе:
SELECT transaction_id, customer_id, transaction_amount,
LAG(transaction_amount, 1) OVER(PARTITION BY customer_id ORDER BY transaction_date) AS previous_transaction
FROM transactions;
Заключение
Знание того, когда использовать GROUP BY, а когда PARTITION BY, очень важно для анализа данных. Помните, что GROUP BY отлично подходит для обобщения данных и получения итогов для различных групп строк, а PARTITION BY — для более детальных расчетов в конкретных разделах данных. Если вы хорошо освоите оба способа, то сможете эффективно выполнять все виды запросов к данным с помощью SQL.
Ниже приведен скрипт с данными, использованными в приведенных выше примерах:
CREATE TABLE [dbo].[transactions](
[transaction_id] [int] NOT NULL PRIMARY KEY,
[customer_id] [int] NULL,
[account_id] [int] NULL,
[transaction_date] [date] NULL,
[transaction_amount] [decimal](10, 2) NULL,
[transaction_type] [varchar](50) NULL
)
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (1, 101, 1001, CAST(N'2024-01-01' AS Date), CAST(1000.00 AS Decimal(10, 2)),'deposit')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (2, 102, 1002, CAST(N'2024-01-02' AS Date), CAST(500.00 AS Decimal(10, 2)),'deposit')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (3, 101, 1001, CAST(N'2024-01-03' AS Date), CAST(-200.00 AS Decimal(10, 2)),'withdrawal')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (4, 103, 1003, CAST(N'2024-01-04' AS Date), CAST(700.00 AS Decimal(10, 2)),'deposit')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (5, 101, 1001, CAST(N'2024-01-05' AS Date), CAST(300.00 AS Decimal(10, 2)),'deposit')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (6, 102, 1002, CAST(N'2024-01-06' AS Date), CAST(-100.00 AS Decimal(10, 2)),'withdrawal')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (7, 104, 1004, CAST(N'2024-01-07' AS Date), CAST(1200.00 AS Decimal(10, 2)),'deposit')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (8, 104, 1004, CAST(N'2024-01-08' AS Date), CAST(-300.00 AS Decimal(10, 2)),'withdrawal')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (9, 101, 1001, CAST(N'2024-01-09' AS Date), CAST(400.00 AS Decimal(10, 2)),'deposit')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (10, 102, 1002, CAST(N'2024-01-10' AS Date), CAST(600.00 AS Decimal(10, 2)),'deposit')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (11, 103, 1003, CAST(N'2024-01-11' AS Date), CAST(-150.00 AS Decimal(10, 2)),'withdrawal')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (12, 101, 1001, CAST(N'2024-01-12' AS Date), CAST(250.00 AS Decimal(10, 2)),'deposit')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (13, 105, 1005, CAST(N'2024-01-13' AS Date), CAST(900.00 AS Decimal(10, 2)),'deposit')
INSERT [dbo].[transactions] ([transaction_id], [customer_id], [account_id], [transaction_date], [transaction_amount], [transaction_type]) VALUES (14, 105, 1005, CAST(N'2024-01-14' AS Date), CAST(-400.00 AS Decimal(10, 2)),'withdrawal')
P. S. В качестве IDE использовалась Microsoft SQL Server Management Studio.
Читайте также:
- Освойте оконные функции SQL раз и навсегда
- Продвинутые темы SQL для дата-инженеров
- Полное руководство по CASE WHEN в SQL
Читайте нас в Telegram, VK и Дзен
Перевод статьи Luchiana Dumitrescu: SQL Essentials: GROUP BY vs. PARTITION BY explained





