
Вступление
Написание кода и поддержание его в идеальном состоянии — дело сложное и хлопотное. Особенно нелегко приходится с нестандартными проблемами, которые предполагают несколько решений, а какое из них правильное — определить трудно.
Тем не менее программирование на высокоуровневых языках можно упростить с помощью определенных приемов. В этой статье мы расскажем, как оптимизировать написание функций.
#1: Ввод/вывод
Для начала подумайте, для чего вы создаете функцию. В конечном счете, ее предназначение — это возврат или изменение чего-либо. Спросите себя: “Что нужно сделать, чтобы достичь этого?”.
Без четкой установки писать функцию просто не имеет смысла. Сначала решите, что хотите получить от нее — это и будет вывод. Затем подумайте, что нужно добавить, чтобы добиться этого результата. И только после этого приступайте к написанию. В некоторых случаях может быть полезно запустить функцию с возврата.
Следующий пример, хотя и относительно прост, может наглядно продемонстрировать эту концепцию. Напишем функцию для вычисления среднего значения.
Для начала определимся с выводом. Нам надо получить вычисление среднего значения. Подобные данные обычно хранятся в векторе или списке на Python, поэтому можно предположить, что это ввод:
def mean(x : list):
return(mu)Как теперь перейти от списка к среднему значению? Просто заполните пробелы и верните нужное значение:
def mean(x : list):
mu = sum(x) / len(x)
return(mu)#2: Извлечение
Еще одна полезная практика написания функций — это извлечение, которое является важным компонентом очистки кода. Извлечение — это создание большего количества методов для обработки данных внутри одной функции. При этом функция не должна быть перегружена сбором различных значений. Вместо этого лучше написать функцию для получения этих значений. Секрет хорошего кода — простые функции с краткими директивами.
Перед демонстрацией упрощенного примера на Python посмотрим, как работает эта техника при написании функций на языке Julia:
function OddFrame(file_path::String)
# Метки/колонки
extensions = Dict("csv" => read_csv)
extension = split(file_path, '.')[2]
labels, columns = extensions[extension](file_path)
length_check(columns)
name_check(labels)
types, columns = read_types(columns)
# Coldata
coldata = generate_coldata(columns, types)
# Head
"""dox"""
head(x::Int64) = _head(labels, columns, coldata, x)
head() = _head(labels, columns, coldata, 5)
# Drop
drop(x) = _drop(x, columns)
drop(x::Symbol) = _drop(x, labels, columns, coldata)
drop(x::String) = _drop(Symbol(x), labels, columns, coldata)
dropna() = _dropna(columns)
dtype(x::Symbol) = typeof(coldata[findall(x->x == x, labels)[1]][1])
dtype(x::Symbol, y::Type) = _dtype(columns[findall(x->x == x, labels)[1]], y)
# тип
self = new(labels, columns, coldata, head, drop, dropna, dtype);
select!(self)
return(self);
endКак видите, из функции извлечено все, что нельзя записать менее чем в три строки. Если бы все эти функции были записаны как одна, то она была бы слишком длинной. Кроме того, было бы практически невозможно отслеживать шаг за шагом процесс ее создания.
Еще одна серьезная проблема, с которой можно столкнуться, — трассировка стека. Намного сложнее отследить в стеке ошибку, если она содержится в огромной функции. При каждом получении трассировки стека мы получаем функции, выходящие друг из друга там, где произошла ошибка. С учетом этого, мы можем видеть точный вызов в каждой функции с ошибкой.
Пример на языке Julia может быть немного непонятен, особенно тем, кто пишет на Python. Чтобы лучше разобраться в этой концепции, создадим функцию нормализации, которая использует извлечение более простым способом.
Обратите внимание, что все эти функции доступны в библиотеках, которые можно импортировать. Но сейчас мы говорим о самостоятельной реализации.
from numpy import sqrt
def norm(x : list):
mu = sum(x) / len(x)
x2 = [(i-mu) ** 2 for i in x]
m = sum(x2) / len(x2)
std = sqrt(m)
return([(i - mu) / std for i in x])Начнем с первой строки. Учитывая, что этот пакет вычисляет норму данных, можно предположить, что он будет ориентирован на статистику. Тем не менее среднее значение, вероятно, будет использоваться не только в этой функции, а гораздо чаще.
Это однострочная операция, но, скорее всего, мы будем применять ее чаще. Кроме того, всегда лучше свести операции внутри основной функции, подобной этой, к минимуму. Конечно, это не самый сложный пример, но достаточно показательный.
Далее вычисляем x², то есть xbar² для xbar в x. Как видите, это просто значение, которое нужно, чтобы получить стандартное отклонение в функции. После этого пишем мы выписываем арифметику и повторяем тот же самый код, чтобы вычислить среднее значение. Наконец, мы получаем стандартное отклонение, а затем возвращаем нормально распределенные данные.
Этот метод, безусловно, можно улучшить. Вместо того, чтобы помещать всю арифметику стандартного отклонения внутрь функции, сделаем для нее вызов метода. То же самое используем и для mean, что позволяет сократить ее до трех строк.
def mean(x : list):
return(sum(x) / len(x))
def std(x : list):
mu = sum(x) / len(x)
x2 = [(i-mu) ** 2 for i in x]
m = sum(x2) / len(x2)
return(sqrt(m))
def betternorm(x : list):
mu = mean(x)
st = std(x)
return([(i - mu) / st for i in x])Единственным недостатком этой версии является то, что среднее значение вычисляется дважды: внутри области видимости betternorm() и std(). Конечно, и этот недостаток можно исправить. Но, учитывая незначительность затрат на производительность, необходимых для компромиссного решения, можно считать его наиболее приемлемым.
#3: Именование
Многие не думают о том, как важно дать функции правильное имя. В большинстве случаев оно должно сообщать о том, что выводит функция.
Кроме того, докстринги используются, только чтобы определить, как должен быть отформатирован вход и какие типы можно ожидать, передавая их на вход. Допустим, следующая функция заставляет «Джерри» съесть «огурец» (pickle):
def pickle(n_pickles : int):
passИмя “pickle” не очень специфично. Дело в том, что вашим коллегам будет тяжело догадаться, кого накормят огурцом с помощью этого метода. Поэтому функция должна называться примерно так:
def jerry_eat_pickle(n_pickles : int):
passЭтот простой пример показывает, как важны имена. И выбор наиболее подходящего — секундное дело. Например, если нужно выполнить операцию слияния со словарями Pandas, на ум сразу приходит слово merge (слияние). Называть функцию mer() или m() — не самая лучшая идея.
Другой аспект проблемы именования заключается в том, что, согласно соглашению, методы в Python должны быть названы в нижнем регистре без заглавных букв. Псевдонимы с заглавной буквы должны быть зарезервированы для типов.
Еще одна проблема — именование отдельных частей функции. Вернемся к примеру на Julia — там нет избыточных комментариев. Конечно, одно дело, если вы пытаетесь объяснить что-то шаг за шагом, другое — подобные комментарии:
# multiply 5 by x
5 * xЕще одно преимущество именования заключается в том, что заставляет программистов группировать различные данные. Это намного облегчает чтение кода, поскольку позволяет читать не все сразу, а постепенно.
#4: Избегание переписываний
Повторяться плохо. Во многих случаях избежать этого можно с помощью извлечения. Тем не менее вы можете столкнуться с ситуациями, когда придется переписывать один и тот же код снова и снова. Это довольно проблематично, поэтому лучше найти способ этого избежать.
Не будем забывать, что модули загружаются в память и/или кэш. Это означает, что всякий раз, когда загружается модуль, каждый его символ помещается в память. Учитывая это, важно свести повторения к минимуму. Лучшее, что можно сделать, — писать код, который будет работать лучше и эффективнее.
#5: Меньше — значит лучше
Всегда лучше меньше кода, чем больше. Это снижает затраты на производительность и повышает читабельность. Python не славится скоростью, однако относительно прост и удобен для начинающих.
Поскольку мир данных в настоящее время сосредоточен вокруг Python, и эта статья тоже посвящена ему, производительность может уступить место читабельности. Тем более, во многих случаях более лаконичные решения оказываются быстрее.
#6: Ограничение типов
Огромная ошибка, которую совершают многие новички, приступая к разработке первых модулей и функций на Python, заключается в том, что они не ограничивают типы аргументов. Существует множество причин, по которым это нужно делать. Начнем с самой элементарной. Рассмотрим следующую функцию:
def add5(x):
return(x + 5)Передача в эту функцию строки вызовет ошибку, как показано ниже:
add5("hello")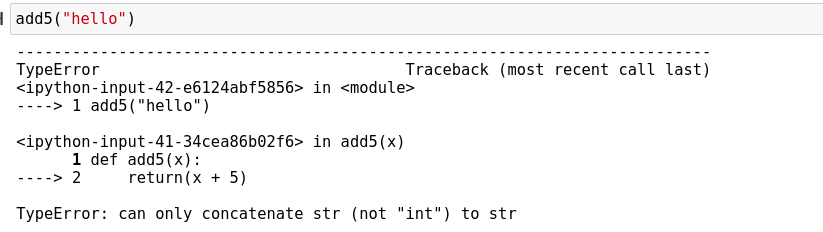
Некоторые быстро распознают эту ошибку и изменяют строку на целое число, а другие могут не понять, в чем дело. Особенно, если учесть тот факт, что x указан первым. Throw может посчитать, что тип предоставляется для добавления строки, а не целого числа.
Вы, конечно, можете избежать проблемы, получив на Github лаконичный дельный совет. Хотя для Python эта проблема не так актуальна, в других языках (особенно в Julia) установка типа аргументов очень важна!
Еще одна причина установить тип аргументов — необходимость уведомить интерпретатор о том, с каким типом вы работаете в функции, до того, как он будет передан. Это может быть полезно не только интерпретатору, но и ускорить работу программы!
#7: Докстринги
Докстринги необходимы — без них вы не сможете работать эффективно, потому что трудно запомнить, что делает разбросанный по 10 файлам модуль из 10 000 строк кода в каждом отдельном качестве.
Докстринги важны не только для конечных пользователей, но и для разработчиков. В совместном проекте они будут незаменимы для написания функции, над которой может работать вся команда на протяжении создания всего кода. В следующий раз, когда будете писать функцию, не оставляйте заголовок функции пустым:
def add5(x: int):
return(x + 5)Вместо этого, задокументируйте!
"""Adds five to an integer"""
def add5(x: int):
return(x + 5)#8: Минимальная вложенность
Еще одна распространенная ошибка новичков — слишком большая вложенность. Этот термин новый уровень области видимости в программе. Например, чтобы начать модуль в Julia, используется module, и тем самым создается первый уровень вложенности. Область видимости больше не является глобальной, а работа происходит внутри более “низкой” области видимости. Мы объявляем функцию внутри этого модуля, и таким образом появляется еще один уровень.
Однако, когда программисты говорят о вложенности в негативном контексте, они имеют в виду вложенные циклы и вложенные условия. Каждый цикл for и условие соответственно имеют свою область видимости. Примером вложенного цикла for может быть следующий:
for i in range(1, 5):
for i in range(1, 3):
print(i)Теперь for будет вызываться каждый раз, когда вызывается цикл, в который он вложен. Излишне говорить, что это снижает производительность ПО. Тем не менее есть случаи, когда такую вложенность необходимо использовать, но их не так много. Лучше всего добавлять вложенный цикл for только для:
- создания прототипов;
- решений, когда все другие варианты исчерпаны.
#9: Декораторы Python
Недооцененная часть Python — это возможность использовать декораторы для полного изменения работы класса. Кто бы мог подумать, что можно полностью изменить характер кода или повысить его эффективность и скорость, добавив простой декоратор в верхнюю часть функции?
Чтобы извлечь максимальную пользу из функций и классов, при программировании на Python следует обратить внимание на декораторы! Они невероятно просты в использовании и эффективны — от повышения скорости работы кода до полного изменения парадигмы Python. И все это можно сделать в одной строке с помощью одного вызова.
#10: Комментирование кода
Одна из часто встречающихся ошибок заключается в неправильном использовании комментариев к коду. Если в файле 500 строк кода и 500 строк комментариев, то вы, вероятно, используете их неправильно. Избегайте очевидных замечаний, таких как:
# получить параметры
parameters = get_params(data)Во-первых, переменная, которой мы присваиваем значение, называется parameters, поэтому легко предположить, что мы получаем параметры. Во-вторых, даже если бы переменная имела случайное имя, функция называется get_params. Когда комментарии сопровождают каждую строку кода, он выглядит загроможденным. К тому же, эта практика не соответствует PEP (протоколу пакетной обработки данных).
#11: Использование лямбды
Еще один крутой лайфхак по написанию функций — не писать их вообще. Вместо этого лучше создать выражение, используя ключевое слово lambda. Это превратит функцию Python в однострочное выражение, стоящее целого массива. Это намного лучше, чем традиционные итерационные методы. Лямбду невероятно легко использовать, и это можно сделать так же, как в примере с функцией mean, которую мы написали ранее:
mean = lambda x: sum(x) / len(x)Теперь мы можем вызвать ее, как если бы написали функцию:
mean([5, 10, 15])
10Конечно, этот простой пример только показывает, как лямбда может быть использована для сведения функции к одной строке. Настоящая сила этого приема проявляется, когда выражение с ключевым словом lambda используются с другими функциями.
#12: Избегание ключевых слов (по возможности)
Последний совет: избегайте аргументов с ключевыми словами. Конечно, это не значит, что их совсем не стоит использовать. Они невероятно полезны, особенно для таких элементов, как параметры, которые используются при построении графиков или в программах машинного обучения.
Аргументы стоит применять лишь для определенных целей, а остальных случаях избегать! Во-первых, они вредят типу. Во-вторых, серьезно влияют на производительность.
Заключение
Эти подходы помогают писать более эффективные и лаконичные функции на Python. Конечно, ни одна функция не получится идеальной с первого раза. Но, используя эти советы, вы сможете сделать хотя бы первую ее версию более качественной!
Читайте также:
- 4 техники Python для краткого кода
- Пространства имен и области видимости в Python
- Как вычислить миллионное число Фибоначчи на Python
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Emmett Boudreau: 12 Of My Favorite Python Practices For Better Functions




