
Любому, кто начинает работать с нейронными хэшами, очень быстро становится ясно: многие сферы применения ИИ могут перейти от векторов к структурам на основе хэшей. И это способствует значительному ускорению развития искусственного интеллекта. Предлагаем краткий экскурс в теорию нейронных хэшей с размышлениями над тем, почему она может оказаться по-настоящему прорывной.
Хэши
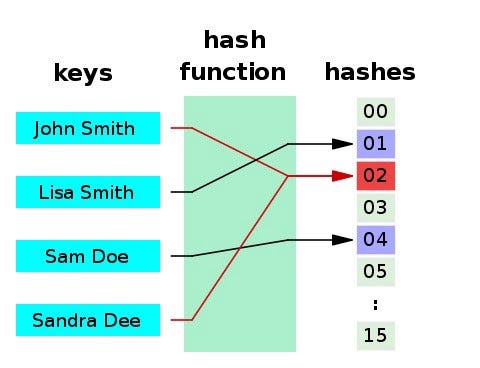
Хэш-функция — это любая функция, которая может использоваться для сопоставления данных произвольного размера с фиксированными значениями. Возвращаемые хэш-функцией значения называются хэш-значениями, хэш-кодами, дайджестами или просто хэшами.
Можете прочитать больше о хэшах здесь.
Хэши отлично подходят для определения компромисса скорость-точность, размера хранилища данных, производительности, скорости поиска и выборки и многого другого.
Важно отметить, что они являются вероятностными по своей природе. Поэтому несколько входных элементов потенциально могут использовать одни и те же хэши. Это интересно, потому что по сути компромисс заключается в отказе от более низкой точности ради супероперативного определения высокой вероятности. Аналогией здесь может служить сравнение 1-секундного перелета (в какое-нибудь случайное место, которое может оказаться в любом городе мира) и 10-часовой поездкой (в результате которой вы попадете в конкретный дом города по выбору). Первое почти всегда лучше; сориентироваться на местности за 10 часов — проще простого.
Что касается векторов, то числа с плавающей запятой (floats) — это представление данных по выбору. По сравнению с хэшами, они более абсолютны по своей природе, но все же не являются точными.
Числа с плавающей запятой
Чтобы разбираться в ИИ, нужно понимать, как компьютеры представляют нецелочисленные числа. Можете прочитать об этом здесь.
Проблема с числами с плавающей запятой заключается в том, что они занимают приличное место, довольно сложны для выполнения вычислений и все еще являются приблизительными. Слушая, как Роб Пайк рассказывает о калькуляторе сверхбольших чисел, я, пожалуй, впервые задумался об этом. С тех пор меня очень беспокоит эта проблема. Спасибо, Роб 😁.
Двоичное представление может сильно отличаться для небольших числовых изменений (при векторных вычислениях), которые практически не влияют на прогнозирование модели. Рассмотрим конкретный пример.
Сравним 0,65 и 0,66. В двоичном формате float64 (64 бита с плавающей запятой) их можно представить двумя двоичными числами соответственно:
11111111100100110011001100110011001100110011001100110011001101
11111111100101000111101011100001010001111010111000010100011111
Разницу заметить нелегко, но можно: почти половина (25 из 64 бит) отличаются с числовым изменением в 1%! При вычислении матрицы с использованием векторной арифметики эти два числа очень, очень похожи. Но в базовом двоичном коде (где происходит вся тяжелая работа) они находятся в разных измерениях.

Наш мозг определенно так не работает. Он явно не использует для запоминания чисел двоичные представления с плавающей запятой. Наши нейроны воспринимают такую информацию как полную нелепицу. Исключением являются люди, способные запомнить более 60 000 знаков после запятой числа Пи, что я не могу себе даже вообразить. Мозг большинства из нас воспринимает лишь визуальную информацию. Нейронные сети нашего мозга отлично справляются с визуализацией дробных чисел, представляющих интенсивность и тому подобное. Но если речь заходит о половине или четверти, держу пари, вы сразу же представляете себе что-то вроде стакана, наполненного наполовину или на четверть, или разрезанную на части пиццу, или что-то типа того. Вряд ли вы представляете себе числа в виде мантиссы и порядка (показателя степени).
Существует несколько традиционных подходов, используемых для ускорения вычислительных операций с числами с плавающей запятой и сокращением занимаемого ими пространства. Один из них заключается в снижении разрешений до float16 (16 бит) и даже float8 (8 бит), что позволяет во много раз ускорить вычисления. Недостатком здесь является очевидная потеря в разрешении.
Следует ли из этого, что векторная арифметика медленная / плохая?
Не совсем. На разработку этой теории исследователи потратили не один год. Аппаратное обеспечение микросхем с наборами инструкций были созданы для повышения эффективности и ускоренной параллельной обработки большего объема вычислений. Процессоры GPU и TPU продолжают использоваться, еще быстрее выполняя операции векторной арифметики с массивами чисел с плавающей запятой.
Вы можете использовать прямое вычисление с большей скоростью, но нужно ли вам это? Вы также можете отказаться от высокого разрешения, но опять же, нужно ли вам это? В любом случае числа с плавающей запятой тоже не являются абсолютными. Здесь речь идет не столько о медленной работе, сколько о более быстром продвижении.
Нейронные хэши
Двоичные сравнения, такие как XOR для наборов битов, могут быть вычислены намного быстрее без участия float-арифметики. Что, если представить 0,65 и 0,66 в двоичном локально-чувствительном хэш-пространстве? Может ли таким образом сделать модели намного быстрее с точки зрения вывода?
Примечание: рассмотрение одного числа — это искусственный пример; но для вектора, содержащего массу чисел с плавающей точкой, хэш может выразить в сжатом виде взаимосвязи между всеми измерениями, и это нечто потрясающее.
Для этой задачи используют семейство алгоритмов хэширования, называемое локально-чувствительным хэшированием (LSH). Чем ближе исходные элементы, тем чаще количество битов в их хэшах совпадает.

Однако в этой концепции нет ничего нового, за исключением того, что новейшие технологии обнаружили дополнительные преимущества. Исторически LSH использовало такие методы, как случайные проекции, квантование и тому подобное. Но у них был недостаток в том, что для сохранения точности требовалось большое хэш-пространство, поэтому преимущества практически сводились на нет.
Но то, что тривиально для одного числа с плавающей запятой, впечатляет в отношении высокоразмерных векторов (с массой чисел с плавающей запятой)!
Таким образом, новая технология с нейронными хэшами (иногда называемая learn-to-hash, или “обучением хэшированию”) заключается в замене LSH-методов хэшами, созданными нейронными сетями. Полученные хэши можно сравнить, используя очень быстрый расчет расстояния Хэмминга, позволяющий оценить их сходство.
Эта технология не так сложна для понимания, как может показаться поначалу. Нейронная сеть оптимизирует хэш-функцию, которая:
- сохраняет почти идеальную информацию по сравнению с исходным вектором;
- создает хэши, намного меньшие, чем исходный размер вектора;
- значительно быстрее осуществляет вычисления.
В результате вы получаете сразу несколько “плюшек” — меньшее двоичное представление, которое можно использовать для очень быстрых логических вычислений с практически неизменным разрешением информации.
Примеры использования
Первой испытательной площадкой для нас стала библиотека Approximate Nearest Neighbors (ANN). Мы исследовали использование нейронных хэшей для плотного поиска информации. Этот процесс позволил нам искать информацию с использованием векторных представлений и обнаружить концептуально похожие явления. Вот почему локальная чувствительность в хэше так важна. Затем мы продвинулись в этом направлении намного дальше и теперь используем хэши гораздо шире для быстрого приблизительного сравнения сложных данных.
Плотный поиск информации
Сколько баз данных вы можете вспомнить? Наверняка немало. А сколько поисковых индексов? Вероятно, очень немного. Причем большинство из них основаны на одной и той же старой технологии. Во многом это объясняется тем, что исторически язык был проблемой, основанной на правилах. Лексемы, синонимы, стемминг, лемматизация и многое другое занимали умы многих продвинутых исследователей на протяжении десятилетий, и до сих пор не все вопросы решены.
Ларри Пейджу (сооснователю Google) приписывают высказывание о том, что проблема поиска вряд ли будет решена при нашей жизни. Задумайтесь на секунду: величайшие умы современности, миллиарды долларов инвестиций — и вряд ли решенная проблема!

Поисковые технологии отстают от баз данных в основном из-за языковых проблем. Но за последние несколько лет мы стали свидетелями революции в обработке языков, и она все еще набирает обороты! С технической точки зрения, мы видим, что нейронные хэши снижают барьеры в развитии новых технологий поиска и баз данных.
Читайте также:
- 3 новых настораживающих примера ИИ-систем
- Как ИИ меняет сферу финансов
- Чем отличается разработка продукта для ИИ
Читайте нас в Telegram, VK и Дзен
Перевод статьи Hamish Ogilvy: “Vectors are over, hashes are the future of AI”





