

Контейнеры существуют долгое время и Kubernetes меняет не только технологический ландшафт, но и организационное мышление. Все больше компаний переходят к облачным технологиям и спрос на контейнеры и Kubernetes растет.
Kubernetes работает на серверах, как физических, так и виртуальных. Облако играет значимую роль в современной IT-индустрии — с ним намного проще реализовать почти бесконечное масштабирование и оптимизировать затраты на рабочие нагрузки.
Прошли времена, когда серверы покупались заранее, подготавливались в стойках и обслуживались вручную. С помощью облака вы можете включать и выключать виртуальную машину за минуты и платить только за инфраструктуру.
Облачные провайдеры, такие как AWS и GCP, предоставляют спот (spot) или вытесняемые (preemtible) объекты по более низкой цене, чем по требованию (on-demand). Одно условие — они могут завершить инстанс в любое время, чтобы вернуть ресурсы. В GCP вытесняемые объекты удаляются автоматически через 24 часа после предоставления.
По данным Google, вытесняемые объекты могут снизить затраты на compute-engine до 80%.
Это беспроигрышная ситуация и для облачных провайдеров, и для пользователей. Первые извлекают выгоду из лучшего использования незанятых ресурсов, и вторые получают ресурсы по выгодной цене, легко выполняя рабочие нагрузки без сохранения состояния.
Где использовать вытесняемые/спот объекты
Подходят ли вытесняемые объекты для всех видов нагрузок? Нет! У них есть крошечная ниша вариантов использования, но они обычно используются для машинного обучения или для работ без сохранения состояния.
Когда вы разрабатываете что-либо для запуска на таком объекте, нужно убедиться, что приложение отказоустойчиво и может восстановиться с точки, с которой оно закончило обработку.
Эти объекты не подходят для приложений с отслеживанием состояния, где долговечность данных имеет первостепенное значение (базы данных). Но если нужно запустить балансировщик нагрузки, кластер Hadoop или что-то, что не зависит от изменений состояния, то они — хороший вариант.
Вытесняемые объекты на GKE
Движок Google Kubernetes Engine (GKE) — это управляемый сервис Kubernetes, предлагаемый Google Cloud. Это один из самых надежных и многофункциональных кластеров Kubernetes, который может создавать пул узлов с вытеснением. Такой метод поможет вам сэкономить при работе с контейнерами.
Если вы используете микросервисы, которые не хранят состояние, при правильной архитектуре можно сэкономить много денег, объединив объекты по требованию с вытесняемыми в отдельных пулах узлами кластера Kubernetes и воспользовавшись функцией его автоматического масштабирования, предоставляемой GKE.
Запуск балансировщиков нагрузки на GKE
Балансировщики нагрузок — дорогостоящие ресурсы и большинство организаций используют контроллеры Ingress для управления трафиком в кластере Kubernetes. При использовании сервисной сетки(Istio) его контроллер Ingress предлагает аналогичную функциональность.
Эти ресурсы не имеют состояния и могут быть хорошими кандидатами для работы на вытесняемых рабочих узлах. Будем использовать гибридную стратегию — нагрузки будут распределяться между вытесняемыми и обычными. Если у нас заберут вытесняемые узлы, надо убедиться, что клиенты не заметят ухудшения в работе.
Установим контроллеры Ingress NGINX в кластере GKE и будем использовать для запуска вытесняемые узлы.
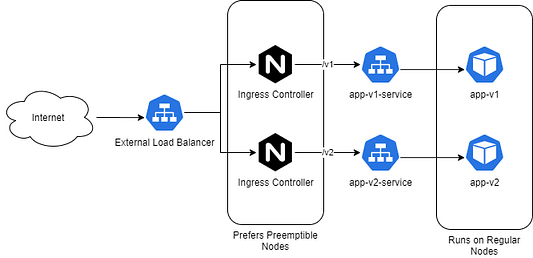
Интернет -> Внешний балансировщик нагрузки -> Контроллеры Ingress /v1 и /v2 (предпочитают вытесняемые узлы) -> app-v1-service и app-v2-service -> app-v1 и app-v2 (запущены на обычных)
Создание кластера
Начнем с создания кластера GKE с двумя рабочими узлами в пуле по умолчанию:
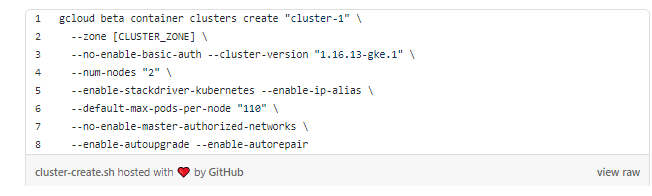
Создадим пул вытесняемых узлов и присоединим его к кластеру:
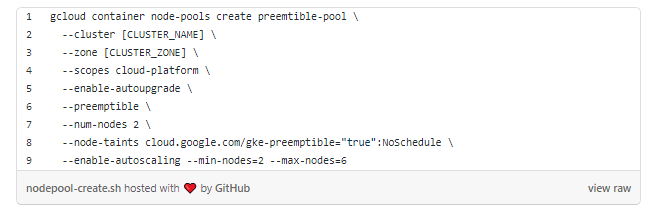
У нас есть кластер Kubernetes с двумя обычными рабочими узлами в пуле default и двумя вытесняемыми в пуле preemtible. Последний имеет включенное автоматическое масштабирование и может варьироваться от двух до шести узлов:
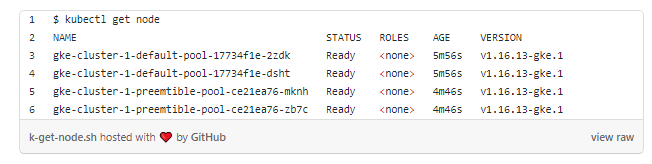
Назначение “заразы” для вытесняемых узлов
Мы также назначили “заразу” пулу вытесняемых узлов, поскольку не хотим, чтобы на них были запланированы все рабочие нагрузки. Также им нужно назначить только поды контроллера Ingress. Остальные поды остаются на стандартных узлах.
Развертывание контроллера Ingress
Скачайте манифест контроллераNGINX Ingress:
wget https://raw.githubusercontent.com/bharatmicrosystems/nginx-lb/master/deploy.yaml
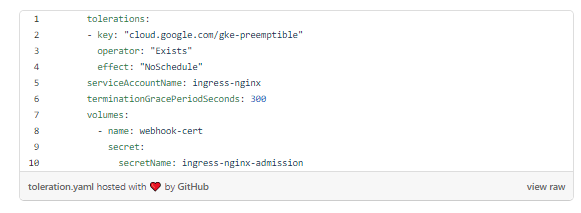
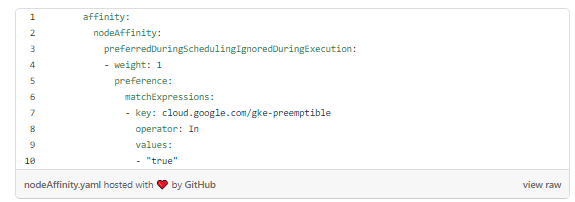
Я изменил его, чтобы включить толерантность к заразе NoSchedule в пуле вытесняемых узлов и подобии узла, чтобы во время планирования предпочесть первое.
Если вы не хотите, чтобы это произошло и Kubernetes выбрал лучший узел, удалите nodeAffinity из deploy.yaml.
Толерантность
Подобие узла
Применение манифеста:
kubectl apply -f deploy.yaml
После развертывания мы увидим под в пространстве имен ingress-nginx:
$ kubectl get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-6b6855f9cb-sj4mw 1/1 Running 0 3m16sПодождем, пока облачный провайдер выделит внешний IP-адрес службе балансировки нагрузки ingress-nginx-controller, а затем укажем службам узнать внешний IP-адрес:
$ kubectl get svc -n ingress-nginx ingress-nginx-controller
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.8.6.193 35.224.126.9 80:32546/TCP,443:32267/TCP 10mСоздадим HorizontalPodAutoscalar для контроллера Ingress для масштабирования внутри кластера. Это необходимо, так как все запросы к рабочим нагрузкам направляются через под контроллера Ingress. Нужно, чтобы они масштабировались вместе с трафиком:
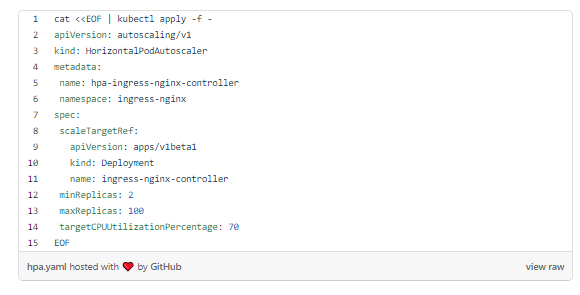
Надо подождать, пока включится HPA. Обнаружится, что nginx-ingress-controller имеет два пода:
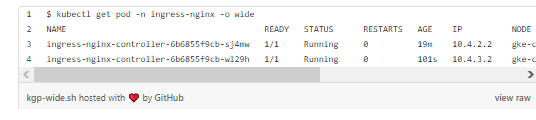
Оба контроллера Ingress предоставлены в вытесняемом пуле. Они предпочитают его, но когда нагрузка увеличивается, мы обнаружим, что контроллеры разрываются по всему кластеру.
Развертка образца приложения
Контроллер Ingress будет обслуживать пример приложения через балансировщик нагрузки. Для понимания работы будет две версии приложения.
Создадим deployment и service для v1:
$ kubectl create deployment app-v1 --image=bharamicrosystems/nginx:v1
deployment.apps/app-v1 created
$ kubectl expose deployment app-v1 --port 80
service/app-v1 exposedЗатем создадим deployment и service для версии 2:
$ kubectl create deployment app-v2 --image=bharamicrosystems/nginx:v2
deployment.apps/app-v1 created
$ kubectl expose deployment app-v2 --port 80
service/app-v2 exposedРазвертывание ресурсов Ingress
Представим app-v1 и app-v2 внешне через ресурс Ingress:
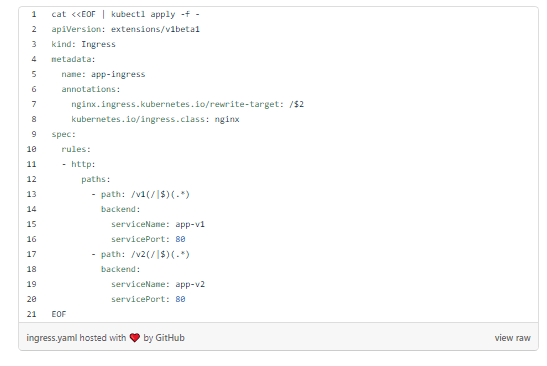
Если мы выполним запрос к контроллеру Ingress балансировки нагрузки с /v1, мы получим ответ от app-v1 (и /v2 от app-v2). Выполним curl:
$ curl 35.224.126.9/v1
This is version 1
$ curl 35.224.126.9/v2
This is version 2Правила Ingress работают.
Нагрузочное тестирование кластера
Проведем нагрузочные тесты. Будем использовать утилиту hey, но можем любой другой.
Мы настроили поды nginx-ingress-controller на автоматическое масштабирование, когда целевая загрузка ЦП превышает 70%, и установили ограничение на 200 милликоров (ядро ЦП, разбитое на 1000) ЦП. Таким образом, все, что превышает 140 м на под, должно запускать другой, чтобы справиться с нагрузкой.
Запланируем 1000 одновременных запросов на 300 секунд для v1 и v2. Это должно запустить несколько копий под в пуле вытесняемых узлов.
Я проведу тесты на двух отдельных терминалах. В третьем терминале запущу watch ‘kubectl top pod -n ingress-nginx’.
Работа с командой hey в первом терминале:
$ hey -z 300s -c 1000 http://35.224.126.9/v1
И во втором терминале одновременно:
$ hey -z 300s -c 1000 http://35.224.126.9/v2
В третьем терминале мы видим следующе — при повышенной нагрузке Kubernetes запускает дополнительные поды контроллера Ingress NGINX:
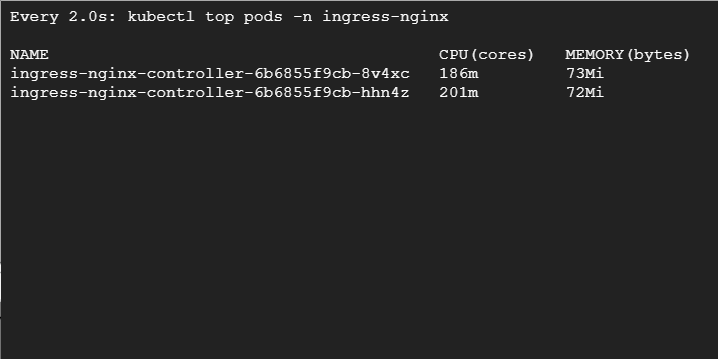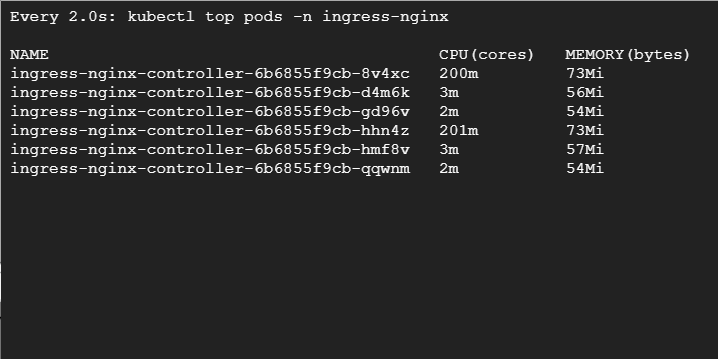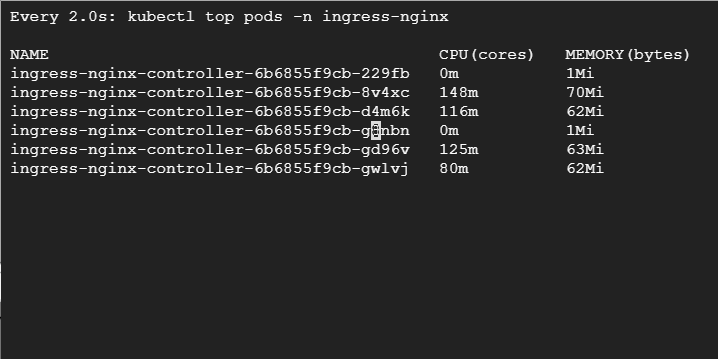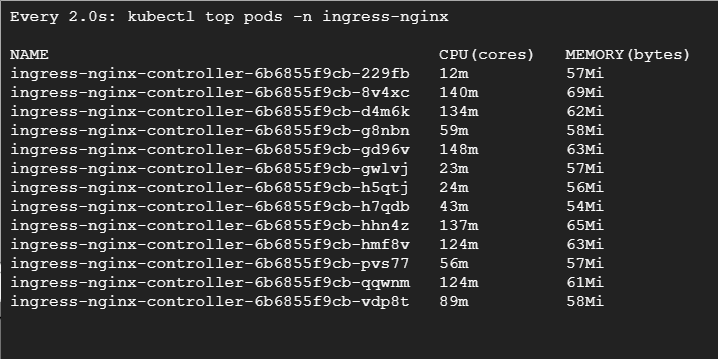
Если мы выполним get pode, то увидим, что большинство появилось в узлах preemptible. Есть один под, который развернут в пуле подов default. Это потому, что по правилам вытесняемые узлы предпочтительнее, но это мягкая проверка — если мы потеряем вытесняемые узлы, поды могут быть развернуты в обычном пуле:
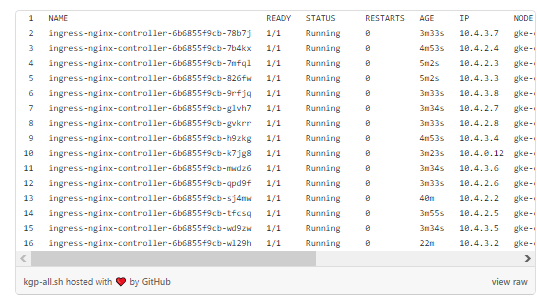
Если мы выполним get node, то увидим автоматическое масштабирование узлов GKE. GKE создала еще один вытесняемый узел в пуле, чтобы справиться с дополнительной нагрузкой.
Вывод
Запуск приложений без сохранения состояния на вытесняемых узлах — это достойная стратегия экономии средств. Приложения можно быстро восстановить или заменить, а если узел удален, они могут быстро переключиться на другие доступные.
Использование вытесняемых узлов для запуска контроллеров Ingress возможно, если уровень качества работы (SLO) приложения может выдержать некоторые ошибки, а высоких требований к доступности нет.
Чтобы запустить новый вытесняемый узел после того, как GCP удалит старый, требуется не больше минуты. Запуск занимает 10 секунд. Нужно решить, позволяет ли SLO прерывать работу на одну минуту каждые 24 часа. Если нет, то вместо этого следует придерживаться обычных узлов.
Вы можете свести к минимуму сбои, создав пул узлов в течение наименее загруженного периода дня. Небольшиевытесняемые узлы в большинстве случаев живут 24 часа, поэтому, вы их теряете, когда пользователей немного.
Кроме того, можно изменить состояние узлов на drain с помощью скрипта завершения работы в его виртуальной машине. Это обеспечит лучшую доступность.
Читайте также:
- Kubernetes: безопасное управление секретами с GitOps
- Практичные Canary-релизы в Kubernetes с Argo Rollouts
- Генерируем образы Docker с помощью Spring Boot
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Gaurav Agarwal: Save Up to 50% of Your Kubernetes Costs With Preemptible Instances





