

В этой статье мы узнаем о возможностях встроенного инструмента утилиты Node под названием fs (file system).
В документации fs говорится:
Модуль fs предоставляет API для взаимодействия с файловой системой схожим со стандартными функциями POSIX образом.
Таким образом, файловая система — это способ взаимодействия с файлами в Node для выполнения операций чтения и записи.
На данный момент файловая система — это огромная утилита в NodeJS, которая обладает множеством необычных функций. В этой статье мы рассмотри три из них:
- Получение информации о файле: fs.statSync.
- Удаление файла: fs.unlinkSync.
- Написание данных для файла: fs.writeFileSync.
Также мы рассмотрим Google Puppeteer — действительно крутой и удобный инструмент, созданный замечательными разработчиками Google.
Что такое puppeteer? В документации сказано:
Puppeteer — это библиотека Node, которая предоставляет высокоуровневый API для управления headless-Chrome или Chromium через протокол DevTools. Его также можно настроить для использования полного (non-headless) Chrome или Chromium.
Таким образом, это инструмент, с помощью которого можно выполнять различные действия, связанные с браузером, на сервере. Например, получение скриншотов и сканирование веб-сайтов, создание pre-render содержимого для одностраничных приложений, а также отправление заявок через сервер NodeJS.
Puppeteer также является огромным инструментом, поэтому мы рассмотрим лишь некоторые из его особенностей, например, создание PDF-файла на основе сгенерированного файла HTML-таблицы. Также узнаем, что такое puppeteer.launch(), page() и pdf().
Таким образом, мы рассмотрим:
- Создание stub-данных (для счетов) с использованием online-инструмента.
- Создание HTML-таблицы с элементами стилизации и сгенерированными данными с использованием автоматического сценария node.
- Проверку на существование файла с помощью fs.statSync.
- Удаление файла с использованием fs.unlinkSync.
- Написание файла с использованием fs.writeFileSync.
- Создание PDF-файла из HTML-файла, сгенерированного с использованием Google puppeteer.
- Преобразование их в сценарии npm для дальнейшего использования.
Здесь можно найти полную версию исходного кода для этого руководства.
Прежде чем начать, убедитесь, что у вас установлены следующие программы:
- Node 8.11.2
- Node Package Manager (NPM) 6.9.0
Начнем!
Шаг 1:
Введите следующий фрагмент кода в терминал:
npm init -y
Этот фрагмент кода инициализирует пустой проект.
Шаг 2:
Затем в этой же папке создайте новый файл data.json и поместите в него mock-данные. Можно использовать следующий JSON-sample.
Получить stub-данные mock-JSON можно здесь.
Структура данных JSON выглядит следующим образом:
[
{},
{},
{
"invoiceId": 1,
"createdDate": "3/27/2018",
"dueDate": "5/24/2019",
"address": "28058 Hazelcrest Center",
"companyName": "Eayo",
"invoiceName": "Carbonated Water - Peach",
"price": 376
},
{
"invoiceId": 2,
"createdDate": "6/14/2018",
"dueDate": "11/14/2018",
"address": "6205 Shopko Court",
"companyName": "Ozu",
"invoiceName": "Pasta - Fusili Tri - Coloured",
"price": 285
},
{},
{}
]Скачать полную версию массива JSON для этого руководства можно здесь.
Шаг 3:
Затем создайте новый файл buildPaths.js
const path = require('path');
const buildPaths = {
buildPathHtml: path.resolve('./build.html'),
buildPathPdf: path.resolve('./build.pdf')
};
module.exports = buildPaths;Таким образом, path.resolve принимает относительный путь и возвращает абсолютный путь к этой директории.
Например, path.resolve('./build.html'); будет возвращать следующее:
$ C:\\Users\\Adeel\\Desktop\\articles\\tutorial\\build.html
Шаг 4:
В той же папке создайте файл createTable.js и добавьте в него следующий код:
const fs = require('fs');
// JSON data
const data = require('./data.json');
// Build paths
const { buildPathHtml } = require('./buildPaths');
/**
* Take an object which has the following model
* @param {Object} item
* @model
* {
* "invoiceId": `Number`,
* "createdDate": `String`,
* "dueDate": `String`,
* "address": `String`,
* "companyName": `String`,
* "invoiceName": `String`,
* "price": `Number`,
* }
*
* @returns {String}
*/
const createRow = (item) => `
<tr>
<td>${item.invoiceId}</td>
<td>${item.invoiceName}</td>
<td>${item.price}</td>
<td>${item.createdDate}</td>
<td>${item.dueDate}</td>
<td>${item.address}</td>
<td>${item.companyName}</td>
</tr>
`;
/**
* @description Generates an `html` table with all the table rows
* @param {String} rows
* @returns {String}
*/
const createTable = (rows) => `
<table>
<tr>
<th>Invoice Id</td>
<th>Invoice Name</td>
<th>Price</td>
<th>Invoice Created</td>
<th>Due Date</td>
<th>Vendor Address</td>
<th>Vendor Name</td>
</tr>
${rows}
</table>
`;
/**
* @description Generate an `html` page with a populated table
* @param {String} table
* @returns {String}
*/
const createHtml = (table) => `
<html>
<head>
<style>
table {
width: 100%;
}
tr {
text-align: left;
border: 1px solid black;
}
th, td {
padding: 15px;
}
tr:nth-child(odd) {
background: #CCC
}
tr:nth-child(even) {
background: #FFF
}
.no-content {
background-color: red;
}
</style>
</head>
<body>
${table}
</body>
</html>
`;
/**
* @description this method takes in a path as a string & returns true/false
* as to if the specified file path exists in the system or not.
* @param {String} filePath
* @returns {Boolean}
*/
const doesFileExist = (filePath) => {
try {
fs.statSync(filePath); // get information of the specified file path.
return true;
} catch (error) {
return false;
}
};
try {
/* Check if the file for `html` build exists in system or not */
if (doesFileExist(buildPathHtml)) {
console.log('Deleting old build file');
/* If the file exists delete the file from system */
fs.unlinkSync(buildPathHtml);
}
/* generate rows */
const rows = data.map(createRow).join('');
/* generate table */
const table = createTable(rows);
/* generate html */
const html = createHtml(table);
/* write the generated html to file */
fs.writeFileSync(buildPathHtml, html);
console.log('Succesfully created an HTML table');
} catch (error) {
console.log('Error generating table', error);
}Разделим этот код на несколько частей и разберемся в каждой из них.
В блоке try/catch мы проверяем, существует ли в системе файл сборки для HTML. Это путь к файлу, в котором сценарий NodeJS будет генерировать HTML.
if (doesFileExist(buildPathHtml){} вызывает метод doesFileExist(), который возвращает значения true/false. Для этого используется:
fs.statSync(filePath);
Этот метод возвращает информацию о файле, например, размер, время создания и т. д. Однако при предоставлении неверного пути к файлу этот метод возвращается в качестве нулевой ошибки, которую мы используем для переноса метода fs.statSync() в try/catch. Если Node может успешно прочитать файл в блоке try, то возвращается значение true. В противном случае выдается ошибка, которую мы получаем в блоке catch, и возвращается false.
Если файл существует в системе, мы удаляем его, используя:
fs.unlinkSync(filePath); // takes in a file path & deletes it
После удаления файла нужно сгенерировать строки для размещения в таблице.
Шаг 5:
Сначала импортируем data.json, а затем повторяем каждый элемент, используя map(). Подробнее о Array.prototype.map() можно узнать здесь.
Метод map принимает метод createRow, который принимает объект из каждой итерации и возвращает строку со следующим содержимым:
"<tr>
<td>invoice id</td>
<td>invoice name</td>
<td>invoice price</td>
<td>invoice created date</td>
<td>invoice due date</td>
<td>invoice address</td>
<td>invoice sender company name</td>
</tr>"const row = data.map(createdRow).join('');
Здесь важна часть join(''), поскольку я хочу связать весь массив в строку.
Шаг 6:
Важной частью является фрагмент, в котором выполняется запись в файл:
fs.writeFileSync(buildPathHtml, html);
Он принимает два параметра: путь сборки (строка) и html-содержимое (строка), и генерирует файл (если он не создан; если он создан, существующий файл перезаписывается).
Примечание: нам может не понадобиться Шаг 4, где проверяется, существует ли файл. writeFileSync выполняет эти действия за нас. Я просто добавил этот момент в код в целях обучения.
Шаг 7:
В терминале перейдите в путь к папке, где находится createTable.js, и введите следующее:
$ npm run ./createTable.js
После запуска этого сценария в той же папке будет создан новый файл build.html. При открытии этого файла в браузере получаем следующее:
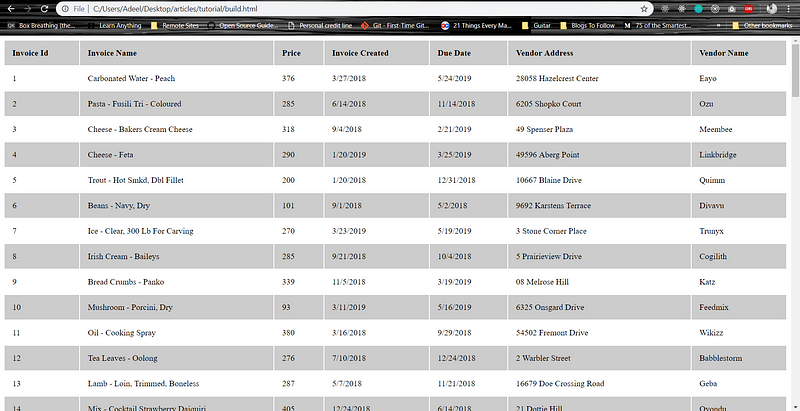
Также можно добавить npm script в package.json:
"scripts": {
"build:table": "node ./createTable.js"
},
Таким образом, вместо npm run ./createTable.js можно просто ввести npm run build:table.
Теперь создадим PDF из сгенерированного HTML-файла.
Шаг 8:
Сначала нужно установить инструмент puppeteer. Перейдите в терминал папки приложения и введите следующее:
npm install puppeteer
Шаг 9:
В той же папке, где находятся файлы createTable.js , buildPaths.js и data.json, создайте новый файл createPdf.js и добавьте в него следующее:
const fs = require('fs');
const puppeteer = require('puppeteer');
// Build paths
const { buildPathHtml, buildPathPdf } = require('./buildPaths');
const printPdf = async () => {
console.log('Starting: Generating PDF Process, Kindly wait ..');
/** Launch a headleass browser */
const browser = await puppeteer.launch();
/* 1- Ccreate a newPage() object. It is created in default browser context. */
const page = await browser.newPage();
/* 2- Will open our generated `.html` file in the new Page instance. */
await page.goto(buildPathHtml, { waitUntil: 'networkidle0' });
/* 3- Take a snapshot of the PDF */
const pdf = await page.pdf({
format: 'A4',
margin: {
top: '20px',
right: '20px',
bottom: '20px',
left: '20px'
}
});
/* 4- Cleanup: close browser. */
await browser.close();
console.log('Ending: Generating PDF Process');
return pdf;
};
const init = async () => {
try {
const pdf = await printPdf();
fs.writeFileSync(buildPathPdf, pdf);
console.log('Succesfully created an PDF table');
} catch (error) {
console.log('Error generating PDF', error);
}
};
init();Как и со сценарием createTable.js, разберем данный код по кусочкам.
В строке 40 вызывается метод init(), который вызывает метод в строке 30. Следует обратить внимание на то, что init() является асинхронным методом. Подробнее об этой асинхронной функции можно узнать здесь.
Сначала в методе init() мы вызываем метод printPdf(), который также является асинхронным методом, поэтому необходимо подождать для получения ответа. Метод printPdf() возвращает экземпляр PDF, который мы записываем в файл.
Какие действия выполняет метод printPdf()? Рассмотрим подробнее.
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(buildPathHtml, { waitUntil: 'networkidle0' });
const pdf = await page.pdf({
format: 'A4',
margin: {
top: '20px', right: '20px', bottom: '20px', left: '20px'}
});
await browser.close();
return pdf;Сначала запускаем экземпляр headless-браузера с помощью puppeteer:
await puppeteer.launch(); // возвращает headless-браузер
Затем используем его для открытия веб-страницы:
await browser.newPage(); // открывает пустую страницу в headless-браузере
Теперь можно перейти на страницу. Поскольку веб-страница находится локально в системе, то нужно следующее:
page.goto(buildPathHtml, { waitUntil: 'networkidle0' });
Важным фрагментом здесь является waitUntil: 'networkidle0;, поскольку он говорит puppeteer о том, что нужно подождать 500 мс до появления сетевых подключений.
Примечание: для открытия веб-страницы с puppeteer нужен абсолютный путь, поэтому мы использовали path.resolve() для его получения.
Если веб-страница открыта в headless-браузере на сервере, то сохраняем эту страницу в качестве pdf:
await page.pdf({ });
После получения pdf-версии веб-страницы нужно закрыть открытый puppeteer экземпляр браузера для экономии ресурсов, выполнив следующее:
await browser.close();
И затем возвращаем сохраненный pdf, который затем запишем в файл.
Шаг 10:
Введите в терминале:
$ npm ./createPdf.js
Примечание: перед запуском сценария убедитесь, что файл build.html сгенерирован сценарием createTable.js. Благодаря этому build.html всегда будет выполняться до запуска сценария createPdf.js. В package,json выполните следующие действия:
"scripts": {
"build:table": "node ./createTable.js",
"prebuild:pdf": "npm run build:table",
"build:pdf": "node ./createPdf.js"
},
При запуске $ npm run build:pdf сначала будет выполнен сценарий createTable.js, а затем createPdf.js. Узнать больше о сценариях NPM можно в официальной документации.
При запуске:
$ npm run build:pdf
Будет создан build.pdf, который выглядит следующим образом:
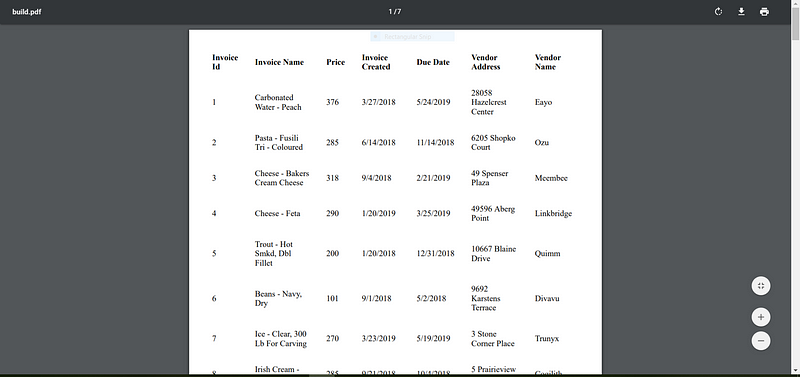
Вот и все.
Мы узнали следующее:
- Как проверить, существует ли файл, а также как получить информацию о файле (в Node).
- Как удалить файл в Node.
- Как записать данные в файл.
- Как использовать Google Puppeteer для генерирования PDF-файла.
Счастливого программирования!
Перевод статьи Adeel Imran: How to generate an HTML table and a PDF with Node & Google Puppeteer





